Transform your data with Azure Data Factory DATA30
How. Many of you have been to the last two, of my sessions, hands up oh wow. You, still want more oh. Yeah. I'm. Gonna give you a full disclosure I what's. The worst thing that can happen at. A conference with 30,000, people where everyone, gets the same bag. Your. Bag gets, picked up mr. :, so. Daniel. Is gonna be supporting me today because I haven't got my own laptop unfortunately. And the, way that the, security, works in our organization. We're. Gonna have to authenticate a few times and Daniel's gonna have to help me out with that authentication, but he's also on, the product group for, Azure data factory as well so you. Know we've got two. For the price of one with Daniel and yeah. He'll, be getting involved with answering some questions as well so there may, be some, delays in authentication. Because I'm on a different laptop. And I'm not getting that pass through authentication. From my normal laptop and if anyone should see a bag with my passport in it I would. Be really grateful if you could return it back or else you're keeping me in America. Okay. So what are we going to cover today well. As, you can see there's no name of the presenter on here today because. There's. Gonna be a few of us helping. You out but we are looking at transforming. Your. Data with, as your data, Factory and for those of you who run the first two sessions we. Talked about. Modern. Data warehousing, in the context, of structured, unstructured data the. Announcement, from Satya, about synapse, analytics. And discussed. How, that works but really the core focus of the first half of this week has, been the exciting. Features, of. Azure. Data facture and i'm super excited to. Show you some things are there that may me go. Right. So. What. Is your data factory this is for the benefit of those people, who, didn't attend, yesterday's. Session, it is a cloud-based, data. Integration. Service, that, allows you to, orchestrate. And automate. Data movements. And better. Transformations. Those. Words have. Been chosen carefully, by. The product group right it. Are castrates. What. That means is on occasions. It will call with. Your choice or the, resources, to actually. Move. And transform. The data that's, up to you, but, with. A new mapping data floor you can also now do your. Own data transformations. Called free, which. Is really. Good because, at the end of the day the, death the data cleansing that you do a lot of it you, just want to get it done pretty quickly right and focus, on the business logic are, your transformations. So. There is a process to this and yesterday. We looked to connect, and collects and we really focus on the copy activity. In getting. Data from various data, sources into sinks, today. We. Focus on transform. And enrich and. Here. We're going to focus on, specifically. At the mapping date of law at all. Not. Tomorrow. What. Day are we on Wednesday. Yeah. So Friday is, a double, hit with, publishing. Yeah. And then, talking. About monitoring. Where, we're actually pushing, the results out to. Synapse. Analytics, or as your sequel there to warehouse. So. What are the components that make up as your data factory well, there's. A link service a link, service is an object, that will store connection. Information essentially, to, both data. Stores, our. Compute. Resources. Right. This, can include as, your hedge the inside as your, data bricks. A whole host of technologies that are available. Now. Once you've got your link, service, you, will then define a data set and the. Data set, is essentially. All, the data that you're working with but. When. You want to perform an operation on. That data you, will do that in what's, called an. Activity. And you. Can have one activity, but. Typically, in as your data factory you're probably building, up multiple. Activities working. In a, pipeline. Now. The pipeline's, important, because, that is a logical grouping, of activities. That. Can be scheduled. Or you can set triggers, on it and by. Setting that what, will happen is the activities, within. The. Pipeline will, process the data and, put, it into the data set. Any. Questions. So far. We. Can parameterize, our. EDF. Solutions. Yesterday. We talked in depth about integration, runtimes. And how. They are important, when transferring. Data. From. On-premises. To, the cloud or. From. Cloud to cloud and, then. We've got control floor, and with, control floor that allows us to control the flow of data transformations.
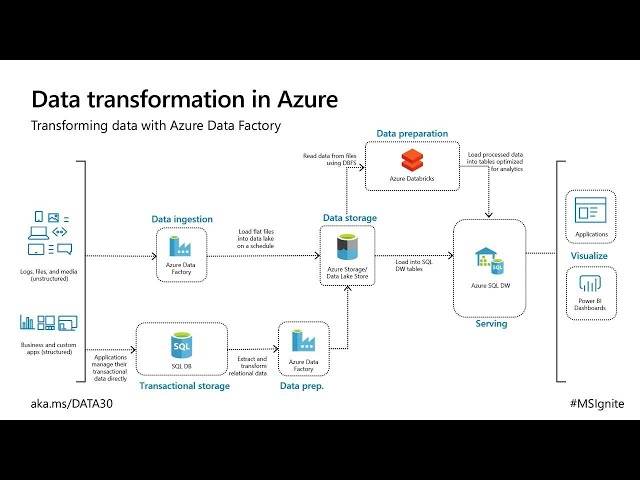
Use. There's. A lot of components, but I like this particular, graphic, that's. Actually come from Docs. Why. Because it shows the component, dependencies, of the core main items, that you're using as your data factory, so. In the. Center is an activity well. An activity, can run on a, link. Service and a link service could be sequel, server it, could be Hadoop, an. Activity. Also. Produces. Datasets. And. It can consume. Data, sets and, data sets. Represents. Better. That. Is stored in a link service. Finally. The, pipeline. Is a logical, grouping, of those activities, does. That make sense any. Questions. So far I, do. Encourage you to use the microphone, for those of you been on many other sessions, it does turn into a question fest sometimes, I do. Actually encourage, people to use the microphones, here, if you have a question to ask we we. Answer, it during, the session, because, we like to capture it within the recording, for people who'll be watching it after the event which, is why we do that. So. Transformations. Really. Really important. Part, of as. Your data factory and specifically. We're going to look at this in the context, of the mapping data floor now. For those of you that have been here. Been. To the last two sessions this should look, familiar. Because this has really been the, learning, path that we've been talking. About from day one right this, architecture. And essentially. Yesterday. A Monday, we talked about the, holistic architecture. Here and we, focused, on their suggestion, into as your data Lex door we. Acknowledge. That you have to manage transactional. Systems, and as, your fact data factory can be used to do both. Essentially. What we're looking at here and. Remember. From, the sessions yesterday things. Are fluid, what. May be good today and may not be necessarily, good tomorrow because of technology, changes, and so forth, but, what we're going to focus on here is, using. As your data factory, to move data, either, into. A data Lex door, well actually what we're going to do we're going to do it in synapse analytics, so. There's been a change already. Now. There. Are multiple ways of, being able to transform, your data right. So. You. May have, situations. Where. You want to. Use. The, capabilities of another technology. So. As your data factory, has the ability, to call a compute. Resource. Now. This. Could be, you. Can you can run out your HD insight on demand right Daniel, we, can make a call to Azure hdinsight on demand I like, that feature because it means I just called the cluster and use, it when I want it we've hedged the inside but we can make use khalsa sequel server we can make new Kolstad theater bricks the whole range of. Technologies. That we can come. The. Big theme yesterday of course was, there. Was a bit of a, discussion around. Well, you know we spent 10 years investing. In sequel server integration services. And I don't, really want to lose all that development, effort, and investment well, you don't have to you, have the ability with Azure data factory to integrate, six packages to. Make use of the. Hours so weeks of investments, in building up that logic, in there and taking. Full advantage of, it here but, what, we're gonna focus on is mapping. Data floor and what, I love about this is it's called free, bitch transformation. At scale right how many people used air dfv one as. Your data factory v1 so. You, know it was, interesting, to configure, right there was a little bit of work involved. And. I know you think I'm being right there but this. This, for, me is a big game-changer within. Our data Factory, because it means that you, know there's a wide range of capabilities, that I can do so, quickly and what. It does is it calls a spark cluster under. The hood yeah. And with. A click of a button five minutes later you're. Good to go, you're, good to go and you. Can focus on what, you want to do which, is delivering, the right information, to the right people getting. The right transformations. Getting the right business logic and not having to provision, resources, to facilitate that. Piece of work does that make sense so. Little, in five minutes you can be up and running with this. So. What is the benefits. Well you can perform data cleansing, transformations. Aggregations. A wide range of things. Called. Free, you. Can build resilient, data flow of you. Can focus, on your business logic. And their transformations. And as, I've mentioned the. Underlying infrastructure. Is provisioned. Automatically. With, cloud, scale, via SPARC execution. Ok, click, of a button all, you have to do click. On the bottom. Very. Simple, to add and. In, the demonstration. You're, going to see us, start. Off where. We finished, yesterday, so, if you were here yesterday, we. Start we created.
A Copy activity. Yeah. And all that that it would just think it ingested, data from a github repo into as. Your data X store that's all we did just literally move there to write, so what we're going to do is now. That that copy activities, added we're gonna add a mapping, data floor and this. One Able's to, configure. In. A really nice offer an environment, our source. Information. Drag. The data floor, into. This and. Then. Perform, our data. Floor work in here now these, are just slides really to give you a heads up of what's coming on but we are going to demo this so. That you can see for yourself. With. That done. You. Can use a wide, range, of, transformations. Ok. On, pivot, derived. Columns. Aggregations. There's. A whole host of. Transformation. Functions, that you can use to get, you on your way and, we're gonna look at about five or six of them into, this presentation. Okay, is there. Any on the screen that are of particular interest, to people in the room. Said. Again. Lookups. Okay cool. Old. Syrah okay, so. Was primers, up for any questions around there so. You, know there's. The list right on pivot, Union, join wind or look. Up the right column, alter, or new. Branch sync. Aggregate. Pivot, filter. Conditional. Split sorts. Exist. Surrogate, key select. Source. And. I'm, read I've read them all out for the benefit of people if you like me up I have bad eyesight, so. Hopefully. That cuz it's on. And. You, simply add these in by clicking on, the plus icon at. The, bottom. Right, of the last object, that you did. Okay. Now. As we've, ever with. As. Your. Data factory once. You've got all this in place. You. Then have the ability to. Trigger. The. Activities, and also. Monitor it as well so you can get a look at how. Pipelines. Are running drill. Down to individual. Activities. Within the pipeline so, you get a sense of. How. Long things are taking if there's any issues, just read, the error messages, right it. Is pretty, pretty. Self-explanatory. With, a lot of the the error codes that come back if you need to fix something, so. From this you, can. Go. To the, trigger button, next to the debug click. On trigger now and, that. Will enable you to define, a new trigger where, you set a schedule you, do it based on an event and you do it through a tumbling, window, choose, you start there any recurrence. You got to go. And. For. Monitoring, you, can view that at the, pipeline and within and within the pipeline there. Is a button for the view activity runs where you can get specific information. Visualizations. Are there for successful, and failed. Failed. Pipeline. And so forth I'm. Just gonna give someone a minute to take the photograph, there, okay. Is there, any questions, at this point. No. So we do the demo then. We'll. Come back to the summary after. So. Believe we. Are. Read. Hey. Daniel can I have your cheers I did, warn you this would happen. Great. When. You use in the, mapping data floor the very first thing that you want to do is you want to switch on there, to flawed debug, right. This. Is going to turn on the. Spark environment. In the background, now. Effectively. You. Don't have to do anything you click the button in the background, a spark. Cluster is being provisioned. So, that it will enable you, to put. The relevant transform, on and, execute. Them as part, of your development environment right, and, don't. Worry if you walk away and have a cuff for the spike clusters and Ronnie does shut down yeah. See how you. Know it's. Not gonna keep, running on there now, this will take a. Few minutes to do but. While we're waiting for that to happen what. We're going to do is add. In a. Data. Floor right, as, you can see here we just click and drag that across and. Then. From here we can either use, an existing debt, floor but in our case we. Are going to basically create. A mapping, data, floor. Now. What that will do is it, will add the, data floor. To. The canvas designer, for our frame but. What we want to do is go back to ingest and transform, where we're doing this work because for, those of you that are familiar with Syst this a little very familiar, we can click and drag and put, that success, criteria. There, any, questions, so far. Once. That's done. We. Click back on here. And go. Back to the data flow itself, and your. Starting, point for this is adding. A source right. Now. Yesterday. We. Focused, on ingestion. And. We. Basically. Move. Data, about. Movies. From. A github repository and. Placed. It in as a delimited, file within. As your debt elect store it was in a file. System or a container called landings, on and I.
Believe We put in output, if I'm not wrong there, might be a slight variation here. Though. What. We're now going to do is we're, going to take. That. Information, indexed, or clean. It up and we'll look at the different methods of cleaning up as I add them on and then. We're going to put it in synapse Analytics. Okay. So. The first thing you're going to do you can see here, that the. Environment. The data for debug environment, that that spark cluster environment that's still, running it, does take about five minutes to, get up and running right but, for those of you it's in my last couple, of presentations, I'd try and do as much as possible life. Okay. So, we click on add source. We'll. Get these tooltips, popping up. But. What we're going to do is, we're going to do a new. As. Your dare to let gen to store oh, sorry. In there Oh. Let's check where that is. Yeah. So we, are in where, are we. Okay. Oh. It's. Already loaded. Excuse. Me. So. I can't hear. Ah. That's, what you were saying you'd already created, that there sorry I apologize, so. Basically the movies err DLS is here, and as, you can see you've got a number of options right, and. What we're going to do now is, once we've defined that, source. We. Can start adding these transformations, but I can't really, want I don't really want to start adding them in until the cluster environment is up and running so I'm just waiting for that to come up and running so is there any questions, while we wear it the next couple of minutes for that to come up. Yes. Can you go to the microphone please. All. Right is there any, reason to choose, SSAS. Over. Data. Flows like. Any advantage. Yes. Share. The. Integration, so is sequel, server integration services, is there any, advantage. That this. Has over the data flows or okay, data, flows basically. Yeah. So the question is is there, any, advantages. Or benefits to, using the data floor mapping, in comparison. To sequel, server, integration. Services, they. Are just basically two different things first, and foremost the right number. One you. Know the sequel server integration services. You probably have already dealing with a lot of on-premises, they're two movements right so. When you're trying to make comparisons with on-premises. To cloud, it's. Not really a level playing field first, and foremostly, and. Mapping. Data flow really, is in response, to customer. Feedback saying. Hey, there's, just the basic, stuff that we do in glit there. Are transformations. That, really. We'd rather just do through a wizard rather than, using, Jason, so. This. This. Capability of this feature has come about directly. Because of that huge, customer feedback, right so, a lot of the stuff that you saw within, sequel, server integration services. That the common transforms, they've. Basically been been, mixed, with in Azure data fact, but. The way that it works here. Is that, it's basically, it's. Basically connecting, up and ruin those transforms, against a spark cluster so. You get the benefits, of parallelism, there and the, performance, level there so, the, short answer I gave you a very long long dance there but the short answer is I don't, think you can do that direct, performance comparison, because they serve different platforms.
Ones On Prem and ones, Kyle does that answer your question, thank. You. So. As you can see now the dirt floor debug, has heated, up and the actual spark cluster is, ready, and. The idea behind this, is that we. Can now go ahead and start, to do. Our various, work so the first thing we're going to do is, we are going to click. On the plus and, you, can see a wide range of. Transformations. There we're going to do a select. And. Within. This away what you'll get here, is different. Properties, popping, up for the different areas so, for example. You've, got a number of different options here you can start to see the data so. We've got movie's, title, genres. Year, ratings, what, rot rot Thom, rotten. So so there's a simple transformation, there already right you, know you rotten. Spell incorrectly. So. You know simple, change there with the selects we can modify. We. Can remove. Columns. If you, so wish so, it's not designed to be anything complex, over than other. Than to. Effectively. Use the Select capability, against you given columns okay. With. That done, one. Of the other things you might want to do is probably. Start. To filter the kinds. Of data that you want to deal with so we. Can do this with a filter transform. And. Within. The filter, you. Can see that you've got access to. An. Expression builder a visual expression builder so, you can use expressions, to build up your transformations. With. This so for example, what, we're going to do is we're going to filter, everything, films. After, 1950. Or something like arts or. Bearing. In mind that it's. Okay. That's. A very simple, expression builder but it is very rich and it's quite flexible. In what you can do with regards to the specific, transforms. You will want to do there to filter the information itself, now. Another, thing to kind of look out here is you do get the ability to start doing data previews, as well we, can refresh that we can start to look at the data as it goes through the pipeline so one of the features that customers ask for is hey, at every single set the, steps that we do the transforms, we want to have the ability to look at that data to make sure that as it, goes through that pipeline. It's, the, output is as we expect, it so, this is just gonna fetch that data back. Give. It a second. So. Let's take a look at the data them so, with regards, to the data. You've. Got move. It you've got title. The. Genres. Are interesting. They seem to be tightly limited. So. Adventure. Pipe comedy, years. And then, of course you've got the correction. With, the. Rotten. Tomato. So. Maybe. You want to clean up some of that a little bit so. One of the ways we can do that is making, use of. Let's. Making use of. Derived. Okay. And. Within, the derived, what, we'll do is we'll, basically. Pick. Out the. First, genre. That's. Listed, in that dataset so you remember how it was pipe delimited, and let's. Say the assumption, is is that the first the. First, genre, is. The. The primary, one right so we'll do that and again, really not.
Too Dissimilar to. The. Filter. What we can do here is. Select. Our, column. Give. It a different name I'm. Sorry, I wish I could spell. And. Then. We can go back into. The. Expression. Builder and. Using. An interactive if statement. And. Then. Embedding, that within a lock it. What. We can then do is, locate. The pipes. I'm. Dealing with in an American, keyboard and the. Pipes in a different, point where Yankees show me where the pipe is. Where. Would have patent where's the papers, right here oh that's. The right way of doing it right yeah okay, I. Did. Give you a warning that things like this would happen right so glad, that Daniels, here today, so. Yeah basically what we're doing is we're locating. The pipe. Within. The, genres. Okay. And then. Using. The left. Yeah. Then we're doing the left to look. He did say it was there right yes. Okay. What. Am I missing there. All. The Karma yeah well sparred. Yeah. Yeah gone, I'm gonna get Daniel to come up because I'm it's. Been a tough day so. I'll kill with a brick yeah, talking with a British government trying to get me passport I. Mean. Another capability, also of the debug cluster is as you're building your expressions, you could actually look at what the output of the expression, is live, and this is actually, doing a spark execution, on the spark cluster so, we spit up an interactive, spark cluster it's a dummy cluster so we only take the first thousand dollars of data unless you specify that you want to do more and within, just a few seconds, instead of having to spit up an entire cluster, do a full spark execution, you, could see okay, now we have the genres, and we. Have four. Genres, adventure comedy and romance war, we're, only going to output at an adventure, into this new column primary genres. Just. To kind of also walk through what this expression is doing. Essentially. We're just trying to see if something has a pipe using the locate, similar, to an index of if you guys are familiar with that syntax if. It's there then we're gonna just. Take everything to the left of that pipe if, it's not there we're just gonna return the column so if there's only one genre we're, just gonna return genres, within, this, expression, language there's like a dozen ways to do the same thing you can use the function, are like really, any way to kind. Of parse the string that, you're comfortable with either if it comes from sequel world accel, world more of a program programmatic, world we try to give you as many different options as possible yeah. So. You click Save and finish if. You go into the data preview again you could get, within. A few seconds, kind of a snapshot of what, the data is at each different transformation, step and, basically. That's just pushing, there pushing it down to the spot closest to bring it back right yep. Exactly. You. Can join me if you want sure. So. Now. We've been able to clean that up right Daniel. To get to get that first that. First. Jar. Madonn let's. Think about some ranking right because now we've got if you look at that data, mm-hmm. We can kind of see so. How can we rank this so. Within a mapping, data flow the way to rank data so say you have a bunch of different comedies, and you want to kind of get a column, that says okay, this is the best comedy the second best comedy the third best comedy yeah this, transformation is actually called the window transformation, okay.
Yep. Within, the window you could specify, a group by column to kind of window over you, could have a sorting, to figure, out how you're gonna rank it what, the actual range is and then what, the actual output of the aggregation is gonna be okay, cool yeah, so I, think in this X. Is the primary column yeah so I define as a primary Sean right if I remember rightly yes. We. Want to we're gonna actually look at for each genre and, each year what's, the highest rated, movie according, to the Rotten Tomatoes rating. Bob Maxson so we're gonna have years and then right that's, true right, this is pair programming, folks we're. Talking through the problem this. Is how we support each other yep. And. The thing, we want to rank it is we're actually interested, like, the highest rated thing will be the thing with the highest Rotten, Tomatoes rating. Okay, so, to get that you essentially, select the column you want to sort by and. You. Figure. Out whether or not you want to do ascending, or descending we're. Gonna descending because we want the top value, to be number. One mmm. When do nulls first although there's no nulls in the data set we're working with so it, really shouldn't be a huge deal. Range. I believe, you want to just you unbounded, yeah just found it and then. Within the window transformation. There's specific ranking functions, that are only available when you're doing this sort of when doing and looking at values, compared to other values in the window itself okay. Yep. So let's call it say ratings, rank yeah. And. Let's, enter, an expression we're. Gonna do a simple rank, function and, if. You are curious. If you hover over any of the expressions, we'll give you an example of what that expression, outputs. So. Let's save and finish. Your. Data preview, see if that's gonna load. Fetching. Data so what's the top part with the number of rows there yeah. Here, you'll, return based. On your data preview, kind, of what insert update delete and absurd, conditions you're kind, of looking at and this sort. Of display, varies, based on the number, be. Based on the data you're looking at the transformation you're doing so because. We haven't specified any, sort of like update or search conditions, we. Everything, is assumed to be inserted. But. We might get to that later if you have some time. So. Here as you could see we, have all of our movies we have the title there's genre. So we didn't delete the existing genres, column we just added a new column primary, genre and then, given the year and the type of movie we actually have the, rank per. John, row yeah so, there's. Only one children's, movie according to this database or the subset of data that came out in 1985, therefore. It's the best, movie within that ranking. The. Way for tonight updation, yes. So let's, bring it all together sounds, good. So. We. Our real goal is to, kind of get an aggregated, data set so say you have you.
Know Millions. And maybe even billions of rows of data coming in you, really are only interested, in it being aggregated together to actually get some sort of I would put that you could easily just point your so your power bi or, maybe. Whatever visualization. Resource, you're using at that data database, yeah, so, we're gonna do that via the aggregation, okay yeah if you guys are coming from the sequel world this is similar to the group by expression. So. Similar. To the actual ranking, we're doing we're going to try to harrogate over the primary, genre and the year and. So. This is going to be, primary. Genre right, and, then, your. Itself yeah for the to mop up the window in right yep yeah so window, one is the incoming, transformation. These are the columns that were referring to within that transformation, that makes sense, where's. Window just adds an additional column aggregation. Affects both the number, of rows and the schema, of the column it'll group, all of the things you do in the group I into. One row per group and then give as many aggregation, columns as possible, although you will use your, existing schema because you're only outputting, the aggregations. That you're doing. So. We're gonna do let's, only do two, aggregations, for Alko we're. Interested in both the average, rated movie and the, highest rated movie, if, you guys remember the. Window. Transformation, output it's sorted data so. We could just take the first of the. Group as the highest rated movie and we're. Gonna use a couple of other expressions, in the expression, builder to calculate the average. So. To add, an aggregation, we're, gonna add to aggregate column called average. Rating and. This. For every genre in here we're. Gonna do the average, which is just the a of AVG. Function, of. The. Rotten. Tomato. Ron. Tomato column, if. You notice these curly braces those are actually escape characters, that. Allow you to take, in any sort of column that comes in and be able to handle it I with. Your data you know you could have odd characters, it, could be in a different language we. Are able to handle it we just if we can't parse, it with the one string we'll add these escape characters and handle it for you so you just cook the column name itself and it'll, pop up.
And. Then. The other aggregation, we want to do is. To. Add the, highest-rated movie so, do that let's call this highest rated, and. Then. We, just take the first. The. First title we find. Now. This, will again we'll have one row per herd, of the group so one, column, a con called primary genre, a con called year and one. Unique. Each will be unique values for that output okay, and then each of those each. Of those rows, will have the, average rating of all movies in that year yeah in the highest-rated movie as well you. Can also look at the inspect. Tab. To really see just more of a metadata view similar. To what you would get in data preview so you could see the type. Type, of values that are outputted. Where. They're out gated as and this is also unique per transformation. So. Let's click refresh. As. This. Is loading oh there, we go oh, there. We go we have and. So, for move so action movies in 1974. The, average rating was 68, and the best movie was Airport 1975. Which. I haven't seen but I thought it was great yeah, I was only just born then Sam. Alright. Now. That we've kind of finished working, with these for transformation, let's uh sink, into synapse analytics, yeah so. Similar. To adding a transformation, you just add a sink right. There. Sorry. If it's the first time you've used data flow you'll get a bunch of tooltips, telling you how to use it we created this new factory just for this demo today so I, believe. We don't actually have a sequel. Data warehouse table that exists yet so let's just. Go, into it we have, a synapse analytics, connection we specified, earlier which, we just connected to via sequence, ocation and. Instead. Of picking, an existing table nice create. A new one let's call it D be owed ignite. Yeah. Demo. That's. Good just. In case. Click. OK yeah yep. It. Allows schema drift so a capability that we didn't cover today is called schema drift but this allows for flexible, handling, of any sort, of columns so if you, have additional columns coming in columns columns coming in with different names you could allow a schema drift and then there's pattern, different pattern matching capabilities, such as batching, based on name conditions, based on column types to really. Handle whatever sort of data might be coming your way with these mapping data flows. Let's. Recreate the table. All. Righty. Just. Cuz we are creating a new table I. Know. Someone, in the room mentioned they were interested in ultra transformation, if you had an alternate row transformation, before a tabular, or, relational. Sync you could actually specify ok, if something matches. A primary, key in the sink then I just want to update it or delete it instead of just assuming it's gonna be an insert, but. Let's go back to the dataflow, activity actually run it all. We have to do is specify. The. Staging link service, and for those of you that all be attending the, fourth session this parts important. To the fourth one as well so. Keep. This in your mind keep this configuration, in your mind. Let's. Uh give, it a little run. So, the, debug capability, to of pipelines, allows you to have, a test pipeline, on the warm debug. Cluster itself instead, of if you ran it a via trigger via a new. Manual. Trigger from a published pipeline, that. Would actually spin up a new job cluster that we then kill, immediately. After your job so you're only paying for using. Spin. Up. Yep. Yes. Here. We. Are using copy. So. So. I'm currently at, this point in time mapping, dataflow supports, six. Or seven, might be seven now because we just added cosmos DB but. It's all azure, cloud based. Sources. So it's data Lake gen1, gen2. Sequel, data warehouse, or known now known as after synapse analytics database. But. Imagine, eight a factory right now with the copy activity, supports over 90 connectors, some, with in Azure some. From on pram, you. Know other third parties such as Oracle, Amazon, Google, cloud so. If you're coming from one of those sources we, found an ELT pattern, where you load all that data into the data Lake and then, you point your mapping data flow at that before writing to your final destination. In that way like we are doing twice. Right so one one Barrett, copy and another, we are doing. Data. Flow so. We can't combine into one okay. We, West said that are fine will be hits that we can have that conversation with, you after if you if you're willing to stay we'll talk through that perfume so, we got a minute left where hot where are we acquiring.
The Computer I'm trying to. Should. Be running I don't know why what's, happening right now. Any. Validation issues. Any. Settings, on the package. Maybe. Because it's creating the table so yeah. Because. I'm staging in Iran I mean, quickly, okay I'll problem yeah sorry. I might, have now just well that's been looked ah, we. Have a github repo, for, you as well, so, you can do this for yourselves. If. You want to get a pen and paper put it in your phone okay. Err dot. M s. Wack. Movies. Analytics. And. If, you go to, that repository, you, can try these, demos, that we're gonna ignite the last the, last few days it's not just this one, you. Can play for it yourself. Yes. Okay. A dot. M s. Wack. Movies. Analytics. Okay. I. Just try to be running it Cyrano. Yeah okay. So we're just waiting for this to finish is there any other final questions sir, yeah the table, that you are creating, what is the format is like a sicko server table. Let's, say I want to add index. How, I. Work. On that final table so you come, to my session, tomorrow and. Friday. Morning. Because. Now we're moving into synapse, analytics, we've got to think about how. What, are the best theater learning practices. Indexer. Statistics. Are one of those key things and just. While we're waiting for that I want to give Daniel a massive, thank you for the support he's giving me today so, I just give him a crown of applause thank you. Because. For me it just thought you, know get. Him up I wasn't in the right frame of mind and I wanted you to have a great experience so. Thank you so much. Has, it been useful. Are. Any of you gonna play around with, that's your data factory dirt floor mapping. Cool. Could. You go to the microphone if you've got a question. And. Then I'm, gonna take two more questions and we're off the stage so. How is this mapping, data flow different, different, than the data breaks options like I see there is a database option so. Mapping. So with data bricks you have to write. Your scholar, code you have to match spin up your own clusters manage your own clusters. They. While they have the same perform, so under. The hood mapping, data flow is actually running as your data bricks as its spar compete service but. We. So. If you optimize essentially, performance, or both they get the peak performance, you're gonna get the same exact performance it's just a different flavor of building the transformations. Some people prefer more, you know are very strong Scala developers, and they prefer you know building on data bricks but, with mapping data flow itself you just all you have to do is drag. And click the actual, transformations. Themselves, you. Just click source you, click, join just specify your logic, instead, of having to worry about like, learning, Scala having. A warning like we spin up the clusters for you you could specify your compute and up you know upgrade, those options, but other.
Than That we really do do everything for you as, much as we can at least that, we can configure. So. Here the source you're, operating on was a adls. File yes, if it was a seek. As, your sequels sequel server so. If, so will, we still use mapping data flow and then we'll, write sequels, for it like no, it's using because, it's using spark that the mapping data flow is using spark under the hood so. So basically, each. You. Put them up in their flow in each. Transforming. It into the skull the relevant language to do that work for you yeah okay okay one. Last question and then we're off the stage for the benefit of the other speaker, to that is that point so that's scar that's being generated. Yeah and you see it can you actually, can. Actually see the code that's generated no. So the clusters themselves are managed by us and like, the way we're generating it is unfortunately, Microsoft IP so we can't share that publicly, but yeah. Is. That do you think is ever gonna be available in the future maybe. We. Don't we don't have any plans to share that actually underlying, code similar to like most like if you're working with the data warehouse not gonna share the actual like dotnet code behind it that makes it happen yeah thank. You welcome. Thank. You very much enjoy, the rest of your night. Appreciate. It and I'll we also be sticking around so if you have any questions, just come up ask us we're happy.
2020-01-23