The future of SQL Server and big data - BRK2229
Okay. Good afternoon everyone, thank. You for coming all the, way down here to the very, furthest. Possible corner, of the building I think. Hopefully. Everybody reached their step goal today, good work. All. Right so I'm Travis, right, this is Roni Chatterjee, we're, PMS on the sequel server engineering, team I'm. Really excited to come and talk to you today about the. Future of sequel server and, what we've announced this week about sequel. Server in Big Data do you guys all hear the announcement, I assume, everybody's here because they heard that not just because they're randomly. Interested, in this right, so. This. Has been a project we've been working on for about a year so far and it's, been kind of as top secret skunk works thing but. In many ways what, we've done here is we're kind of we're really stretching, the boundaries of like, what it means for, like, sequel server is a name right, and, I. Think we're just gonna kind of open. Up sort of a lot of possibilities, for everybody today as we kind of talk through what, we've done here and how this all works so this, will actually be a two-part, session, today. We'll kind of have more of an overview session, with lots of demos and tomorrow, morning at 9:00 a.m. we're. Gonna start with a deeper, dive session. On all this we're doing around sequel server in Big Data and, some. Of the other PM's on our team like, UC and mihaylo will be leading that session tomorrow morning so please come for that one as well hopefully. It's somewhere closer than this one. Okay. It's. The same room you can just sleep here if you want it's fine, you. Don't want to walk all the way back to your hotel you can just stay here alright so let's, get started. Just. To set some context, as, we talk to customers I think, people are starting to feel a little overwhelmed. By all the data that's being generated it's. Getting, pretty crazy and. Something. Like 80 percent of the world's data right now has been generated. In just the last two years. That's. Pretty mind-boggling, and, not. Only is this data being generated at, an ever-faster rate, but. The types of data that we're dealing with are changing. Rapidly as, well and. So. Really as we, try to take some of these challenges, from you know getting insights, out of all this data that we have the. Barriers, to getting that insights is becoming increasingly difficult because, of the complexity, of our systems, the amount of data that we have is just growing, crazy, and, we, have so many different types of data we have data and lots of different types of databases and so on and so. You know it's kind of interesting every year we do this survey. Of a, few hundred customers, and. What we try to do is we try to ask. Questions about what technology, they're using and how they. Are using that to sort, of advance their companies, in comparison, to others and then we look at some of the success, metrics, about these companies like what's. Their operating, margin. How profitable are, they that sort of thing and we, try to drive some insights about how these, successful, companies. Do, things differently when it comes to technology and. Three. Things popped out to us in the survey over the last year or two the, first is that a lot of these companies that are being very successful in the market right now are. Doing their data integration, without using, ETL, they're. Taking approaches, where they are putting their data into, a, central. Data store like a data Lake and then. Accessing. That data from, a different. Patterns, right so maybe you want to access it through sequel maybe you want to use a spark job against with that kind of thing and so, people are trying to centralize, their data into these data lakes and.
We. Also see that the companies that are most successful are, the ones that are embracing using, machine learning and AI to drive predictive, analytics, and. So, as we look at these trends, and what is making for successful, companies and those are the ones that are going to last the longest and drive things further forward, the most we. Want to take a look at how sequel server can help them do, those things even better and so, today what we're going to talk about is how sequel server 2019. With, these big data clusters we're going to talk about is going, to help you do three things first. Is integrate, all of your data regardless. Of where it's at and regardless, of what type of data it is we're. Going to help you manage, all of your data easily. And securely, at the scale and with. Good performance, and we're, going to help you analyze all, of your data and you'll. See here this repeated, pattern of all data. And you'll see what I mean by that as we go through this presentation and, to do, that we want to give you a consistent management experience, and tooling experience, which you'll see in our demos today, so. Let's start with integrating, all of your data so. IDC did a survey, like. It was like 2016. And. They. Asked people about their data movement and what, kind of impact that might have on them and, one of the things that popped out to me was WOW, 75%. Of these companies that are responding the surveys say that the timeliness, of their data is impacting, their business opportunities, because they're moving it through all. These ETL pipelines. Probably. Some of you who probably have a spaghetti of ETL, pipelines, going every, which way inside, of your data architecture. Today and data. Movement while it has its place as a data integration approach, has. Some problems, first, of all it increases, the, cost in terms of duplication, of storage it costs money to build and maintain those, ETL jobs it. Takes time to move that data through your ETL pipeline, it takes time for you to build. The code that actually will move the data before you can actually start using it in your report for example so. When your executive comes to you and says hey I need this report tomorrow you're like oh sorry it's gonna take two months just to build the ETL pipeline and get the schema figured out right, and then actually move the data there before you can even start building the report. Moving. Your data around creating, copies of it increases, your security, risk as well because now you have multiple copies of your data that increases your attack surface area, and you, have potentially, of that data sitting in different database systems, that are secured in different ways and keeping a common, security architecture.
Across Multiple different types of databases is pretty challenging. Lastly. Is you're moving all that data through all of your ETL, pipelines you can introduce data quality, issues and for, companies that have compliance, regulations, like gdpr it can be really problematic when, you have multiple copies of those data all over the place and your users come and ask you to delete that data. Then. You sort of ask yourself like I have no idea how many databases, that's in sorry you know that's not a good answer and so, what. We want to do is we want to give people an alternative in. Addition. To data movement of using data virtualization, and. Data, virtualization, helps address some of these problems by leaving the data in place in whatever system, it's already, but. Yet be able to query it from sequel server using. Tools that you're already familiar with, whether. It's an application framework or power bi or, some other analytics, tool everybody. Knows how to talk to sequel server and now let's make it easy for you to through sequel server go get data from other places and not, make a copy of it but actually query, it from the source at the time the query is issued a sequel server and do. It in a fast way and so we'll talk through how we do that. So. In sequel, Server 2016. We, introduced, the poly based feature you guys probably are familiar with that right and poly. Base enabled. You to query. Sequel, server and hit an external, table that was defined over, HDFS. In a, cloud error or Hortonworks cluster, and when. You issue that query it's a sequel server sequel server will go out and either run a MapReduce job, in the Hadoop cluster and get, the data back or remotely, stream the data from HDFS, and bring it back through sequel server back to whatever query, was, asking for that data and that's, a data virtualization, technique. But. It only worked with cloud era and Hortonworks HDFS. In sequel. Server 2019. We're, taking that same poly based technology. And improving, it and expanding. Upon it to add additional connectors. To more data sources, Oracle. Teradata, other sequel, servers. MongoDB. And any, sort of ODBC, compliant data source you want to hook up to my sequel, or Postgres, go for it you want to hook up to a cloud service like Azure sequel DB or DW. By. All means cosmos DB, no. Problem we tested that out just the other day using. The Mongo DB connector we're able to connect to cosmos DB through the Mongo API. Ok, cool now we can go get data from all over the place bring it back in through sequel server using external tables. So. Let's take a look at an example of, doing this where we'll create an external table, using. The azure data studio external. Table wizard, so, we want to make this as simple as possible how, many people tried to create an external table using poly base and T sequel before it's. Not exactly, simple, right so we want to make it simple for you okay, so what, we're gonna do is we're just gonna come in here right click on this database inside of azure data studio and. We're gonna go to create external, table oh. Hang. On I got the presentation.
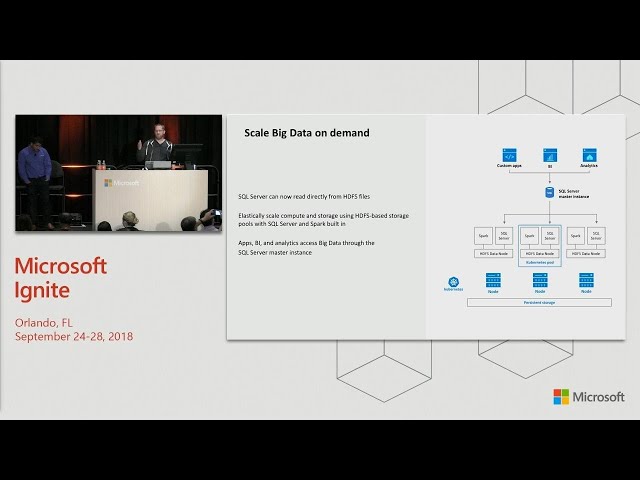
Thank You. Okay. So, this is the external table wizard i just right-clicked on the database and said create external table and i'm. Gonna create it in this sales database, inside of my sequel server I'm going, to choose the Oracle type here and over time we'll add additional types for the other ones like MongoDB. Teradata. HDFS. And generic. ODBC, I just. Click Next, I'm gonna skip over this next screen here where it asked me to create a database master, key because I've already done that and now, we just give this table a name and we call this Oracle inventory. And. We're gonna go to this server here that I've already got set up conveniently. And. Put it in our database name and, we're gonna give we're, gonna create a database scope credential, at the same time. Now. You can see that over here we're going to go and browse to the, schema, that exists in that Oracle database. In real time here and we're gonna choose the table that we want to synchronize over and we. Can even see. You. Know there we go we can even see the schema, of that table and we can do column, mapping if we wanted to, so. If we want to change the names of the columns we want to change the name of the table that's defined in sequel server etc we can do that and, now we create that external table and. We can go back into our database here oh. I. Lost my connection. Okay. Go into our database sales. Tables. Here's. Our Oracle inventory table we just created and we'll just do a select top 1000, over that and. Just. Like any other table inside a sequel server you, just query it you just select star from it you can do column selection and all that kind of stuff you can do predicates and so on you can just go get that data from wherever it's at at the time you've issued the query it's a sequel server what, you guys think pretty cool, okay. So. We. Actually downloaded, it this morning in the overview sessions some people go to that one where they saw using, the data virtualization connector, is an approach to migrate, from Oracle, to sequel server so. You start out by creating an external table over Oracle using, this date of birth wizard here and then, you, put all of your reporting and that kind of stuff on top of that external table and then. You just eventually move all the data over into an actual sequel server table, now you just change the view that you're pointing to you and go, get that data out of the table that exists inside of sequel server so it's a way for you to kind of use this as an approach for data migration, as well. Okay. So. So. That's how we were going to help you do data, integration. Through, data virtualization, makes it easy for you to combine this data together and, because they're just tables inside of sequel server if you want to you can even do joins of the data so for example you, have an external table or Oracle you have an external table over another sequel server you're, actually joining that data together. So. Now let's talk about managing. All of your data and, for. Those people that have deployed a big data cluster you know that it's a big task and sometimes, it's pretty challenging dr. go out there and deploy a big data cluster, so. We want to make this easier, for customers not just to deploy a big data cluster but to integrate together your relational, and Big Data environments, into a single, integrated. Solution, that, is provided, by and supported, by Microsoft. So. To do that as you guys have heard the announcements, this week we, are actually putting spark, and HDFS. And some, other open source Big Data components, like Knox and Ranger in the, box with, sequel server these. Open source technologies, will become a part, of sequel, server and. If you think about it sequel server has always been a scale up database, engine, if you want to manage more data you want to have faster queries you, go to one. Of your favorite OMS, and you buy a bigger server right, and so. Now what we're going to do is we're going to give you this big data architecture, in a way where you can run it on a more flexible hardware. Architecture, that can scale out elastically. By, leveraging the kubernetes, container, Orchestrator. So. Kubernetes, is a way for you to provision, a kubernetes cluster of, available, compute resources and, when. You deploy a sequel server Big Data cluster, on to that kubernetes, as you'll see here in a minute it's a very automated, very simple process to provision, all those containers out on to kubernetes. And upgrade. It very easily I just. Wanted to share with you some of the reactions, we had to the news that was announced this week I got, a really great press coverage, on it lots of great tweets from various, people maybe some of you here in the audience it's, pretty exciting to see the the reaction to this that. Was my favorite one there the holy s1 at the top good, stuff so we're. Really excited about this and we hope you guys are too so what do you guys think is this pretty cool put SPARC and HDFS in the box.
Okay. So. Let's. Take a look at what this architecture, actually looks like so. In, order to like, let's just start at the bottom the foundation, is your storage layer and so in this architecture we'll have a very. Interesting and unique, architecture. On, every. HDFS, data node deployed in the sequel server 2019. Big data cluster you will have an HDFS, data node and, co-located. With it a sequel server instance. And a. Spark engine and. You. Can scale this out, each of these is deployed together in a kubernetes pod and you can scale it out you have so many pods as you want so as you need more storage capacity need, more compute capacity you can scale that out as. Much as you like and as much we have a kubernetes. Architecture. Underlying, that to you know support that capacity, demand now. The nice thing about going on kubernetes is very fast to deploy and easy to apply which we'll see here in a minute it also makes it easy for us to upgrade it will, have an orchestrated, automated, rolling. Upgrade of the whole thing and it. Makes it easy for you to scale it up you want more storage you just deploy more pods you need more compute due to blowing order pods. So. I want to show you how easy it is to deploy a sequel server 2019, big data cluster and, we partnered with our friends, over at HPE they, let us borrow some of their elastic platform. For analytics hardware and, we've. Set it up so that we can actually do a demo of this for you here so. I'm going to pivot over to an RDP, session I have into that environment so I want to show you what this looks like to deploy a sequel. Server 2219. Big data cluster. Okay. So here I have a Windows desktop but I've got some ssh windows going into the, environment i'm going to use this tool called mms equal CTL it's, a python-based command-line, utility, you, can run it on Windows Mac or, Linux I happen to be running it on a Linux terminal here which I'm SSH it into you threw putty and to. Deploy a sequel. Server big data cluster, you. Might think this might take a long time and it might be hard but it's not I just. Run that. I'm. The sequel CTL, create, cluster, give, it a name off it, goes okay. So. Now, what you can see is as these pods start to come up we. Can keep an eye on the progress here, so, first the controller pod comes up and that controls the orchestration, of rolling out everything, else and, you. Can kind of keep an eye on this over time over here we'll, see like right now we have the number of pods distributed. Across these 16 nodes of the, elastic. Platform for analytics cluster from HPE and you'll, see those pods start to come up inside of there now. This takes a few minutes so if, we have time I'll come back towards the end of the session and we'll take a look at how that's going but. That's it very simple. Don't. Want to make it hard. Okay. Now I, want. To talk a little bit more about the architecture. So. The way this works is that you deploy, your what, we call a storage pool of these, pods that contain spark sequel and HDFS, all, together and then. You can issue a query to a sequel, server master, instance, and this master instance in. The near future here, will also be able to be an always-on availability, group deployed on kubernetes we. Just announced the preview of that capability in, general, this, week and that will be available inside of the sequel server 2019, big data cluster here pretty soon so, then you get read scale capacity. And always on a group always, on an availability group level of high availability, inside. Of a sequel server 2019, big data cluster and the. Whole thing is running on top of kubernetes and you have persistent, storage underlying, that to make sure that all of your data is preserved even if a pod for some reason crashes, or even if an entire kubernetes, node. Goes down all, of your data will be persisted. Into that persistent, storage and you, can recover that by, having, the pod be automatically, reprovision to another kubernetes, node because, that's what kubernetes does right, it's an Orchestrator, of deploying these pods.
Okay. So now I want to do another demo, which is creating, an external table, over, HDFS, and in. This example I'm going to create a table that goes over. The. HDFS, inside, of a sequel server 2019 big data cluster. So. To do that I'm, just gonna start here do, a new query. I'm. Going to create an external table now. If you guys remember creating. An external table inside of sequels for 2016, and 17 over HDFS, was pretty involved you had to do, all this stuff to specify, how. To connect to cloud era and Hortonworks that kind of thing in the, case of HDFS, being in the box inside, of a sequel store between 19 big data cluster you don't have to mess around with all of that it's already there and built in and all, you have to do is say that your data source is the sequel storage, pool and, that's, referring, to the HDFS, that's built in inside, of a big data cluster and then. You just give us a path to wherever that data resides, tell, us what type of file it is give us the columns you want to read it the data into and that's, it and now oops too. Far don't to drop the table and. Now we can run this query and actually go get this data out of HDFS, and this was millions of rows of data sitting inside of us he has V file down in HDFS, we're, gonna reach down and get, that data back put, some structure around it and return it back as a sequel server results. Set like you would expect to find from, querying. Any other type of table except in this case it's an external table that, we created over HDFS. I. Really. Hope this works. There. We go. Okay, so there, we go we're reaching down and the. Way this works is that we're. Actually reaching, down to the sequel server instances, that, are co-located, there next to the data nodes in HDFS, and issuing. That query to them and having them get the data and return it back to us. Now. As we saw there the query performance was okay, but. We can make it faster, all. Right we still have a year or more left to do the tuning on this before we release it but there's another technology we want to bring to bear here to, make it easy and fast to do this and that. Is we're going to introduce a caching tier, as part of this architecture. And. So what you'll be able to do is provision, what we call a data pool and a data pool is a set, of sequel server instances, deployed, as containers, on top of this kubernetes, cluster and. You. Can point to an external table. Basically when you create an external table whether, it's over Oracle, or teradata or the HDFS. Inside, of the Big Data cluster or HDFS, and cloud area doesn't matter and you, can say I want you to basically cache this, data inside, of this data pool and you can point to a data pool and. What will happen is we'll go and we'll query. That data from the source. Automatically. Partition, it and spread it across and number, of sequel server instances, that exist in that data pool and store. It inside of MDF files in across, all those sequel server instances, and we're, gonna automatically, put columnstore on top of it to improve performance by caching everything, in memory and then. When we go to do a query over that data the. Local, filtering, and aggregations. Will happen in parallel. In each sequel, server instance. At. You know in parallel, right and then. We return the data back up to the master instance, so we parallel, lies out the execution, of the filters and local aggregations. The. Other nice thing about a data pool is that you can combine data, from multiple data sources together into one data. Pool so. If I had for example an Oracle database and, a MongoDB and, an HDFS, I can, create external tables, over all those cache, them all to the same data pool and then I can create joins across, that data that, are processed, in the data pool.
Okay. Now. There's, another use case for data pools let's. Say you have a data, feed, which, is more of like an append-only, type. Of data feed like an IOT data stream in. This pattern you can say okay I've got this IOT, data coming in I might. Want to write it to HDFS, that's a pretty common pattern but. Maybe I want to also be able to query over it really fast using the sequel server engine I can, take that data partition. It and spread it across a number of sequel server instances, inside of a data pool and from. There I can then query the data where. I have the pattern, of doing the local filters and aggregations, across all the sequel server instances, in parallel. So. This this like take sequel server to a different, dimension right, like where sequel server used to be a scale-up system, it can now scale out with these data pools for these append-only types, of data ingestion patterns. So. This should really boost the performance of, your queries whether you're using the data pools for data virtualization or, for a persistent, storage for a streaming data pool. We. Want to make the performance even faster. So. The way that we're going to do that is we're, going to introduce the concept of a compute. Computer. Simulation. Server instances, deployed, as a compute, pool and then. The compute pool what it does is each sequel server instance, will pull in a partition, of the data from the external data source like, Oracle let's say and then. As those sequel, server, instances, receive, that partition of the data they then work together to. Do cross partition. Aggregations. And shuffling, of the data, so. We can parallel eyes and sort, of separate. Out the, query for. That type of a query off to some separate compute resources from the sequel server master, instance and this. Will really boost performance when you're doing data virtualization queries, whether it's over Oracle, or HDFS. Well. We don't want to stop there, let's. Put compute pools you know over these other external, data sources, then. Let's combine data. Pools and compute, pools. So. As you get data from external data sources or these IOT data streams and you're ingesting that data into the data pools and then. You go to do a hurry over it the. Local, aggregations, and filtering are gonna happen in parallel across a number of sequel server instances. That, you have in your data pool and then, the compute, pool is going to receive all that data and the compute, pool is going to do the cross partition. Aggregations, and shuffling, of the data before. It sends a backup to the master instance. Right. So sort of mind-blowing to think about the compute, power that's available here. Okay. Now we also want to make. The. Management. Of this very, simple so, we're going to provide some. Tooling that you can use which we've seen here a little bit so far as your data studio is the, tool that you can manage to use to manage the whole environment you, can connect to sequel you, can browse your tables, there you can run your queries do all that kind of stuff and you.
Can Connect to the, spark endpoint and submit spark jobs you can browse your HDFS, files and so on one. Tool there's only one I know of like this or you can do everything in one tool. Secondly. We're going to provide a management. Service. As part of this. So. The management service will provision a bunch of agents that run in every pod in the entire architecture, and those agents will collect monitoring, data and all, of the logs back, to in flux DB and elasticsearch. They're provisioned, as part of it and. You. Can use that then through an admin, portal, that comes in the Box browser-based, portal, you, can view all the monitoring, dashboards, there you can do logout analytics using Cubana and the. Admin portal allows you to provision, additional, compute, pools or data pools it helps you manage the security around it and the. Management Service also takes care of the services that you need for doing things like automated, backup. Automatically. Provisioning, high availability for, the always-on availability, group on the master instance. Automatically. Helping you do rolling, upgrades, and all, of these kinds of things the monitoring, and everything it all just comes in the box with the Big Data cluster, and, no. Matter where you deploy this Big Data cluster, whether. It's on a kubernetes, cluster on-premises. Or you, deploy it on a managed kubernetes, service in Azure like aks, or, you deploy it on something like OpenShift on premises, or openshift on Azure or even, a third party cloud like those other guys it, doesn't matter wherever you have kubernetes, you can deploy a sequel server 2019 big data cluster and the, management, experience, comes with it and it's. Consistent, regardless of where you deploy it and. So this is a hybrid technology. That you can deploy wherever, you want. Well. I forgot to advance the slide just, said something all, right okay. Now when it comes to security, security.
Is Is super important, and, it's. Hard to integrate security, between your relational, environment, and your Big Data environment but. When you deploy a big data cluster, the security, comes pre integrated, and it's, integrated, not just between sequel, and the Big Data as part of it but, it's integrated, with Active Directory and, further. Where, we can we, will do impersonation. So when you connect to a sequel server master instance and we need to go out and get data from an Oracle for example we, will impersonate the user going out to get that data when it connects to Oracle. So. This architecture, helps you simplify. Your. Big data. Helps. You deploy it all is one thing helps you operate it and manage it all is one thing and it's all integrated together. Next. We want to talk about how to help you analyze all, of your data and. Analyst. Analytics. Is an interesting thing right, it's a such a fast-moving, and growing area, and everybody. Is trying to learn along, with everybody else and. We. Want to try to make this as simple as possible you know if you were to listen to Satya Nadella he'd say something like we're trying to democratize, AI, you. Know something sort of visionary, like that and, what. That really comes down to is like let's make it simple, for people to use it, so. One. Of the things we want to do is we want to take the ml services, which we've built into the last two releases of sequel server and apply. That at the top tier in that master instance, so. I can have ml services up there and. Now. Not. Only can I train, my models, over, the data that exists inside a sequel server but I can now feed, data through, those external, tables. Easily. Into my model training so. I could create for example an external table over Oracle and then. Do a select, on that from my master instance pull that data in may be pulling some data from HDFS, through another external table join, it together and then, just feed, that into my R or Python script inside of the sequel server master, instance and produce my, model, right there inside of sequel server and once. I've produced the model let's, not go put it someplace else necessarily. We can just put it right back inside of sequel server as a blob inside, of a table and sequel server and then. Let's operationalize. It right, there inside of sequel server as well so. I can just take a stored procedure for example if somebody's gonna call that stored procedure and they're gonna provide me some input parameters, I'm gonna take those input parameters and I'm gonna score it against, that model using. Either R or Python, or the. New native, T sequel predict, function that, we provide out of the box that can do a million predictions, per second and. Then. This what in this pattern, your. Machine, learning, model training, scoring. Operationalization. Everything. Never leaves the boundary of sequel server and. We. Try to make it easy for you to do this by just you just do it inside of sequel server. Now. If, you have spark in the box some new interesting possibilities, open up. Lots. Of data scientists prefer to use spark, they prefer to use languages, like Scala and Python, and R and all, this right and so let's now give them spark but. Let's give them spark that's integrated, into an enterprise ready, security, boundary of sequel. Server and open, up some new possibilities for, them where. They can use Azure data studio to. Browse the data that might exist in sequel, or they, can use notebooks, which we'll see here in a minute to interact, with the data that exists in HDFS, and let's. Open up some possibilities here, so for example I can use data. Studio to query the master instance I can use spark to go and run jobs inside of the storage pool and I, can also query, external, data sources so, now you can imagine a pattern where like for example a spark. Job comes in the spark job connects to the sequel server master, instance which has some external, that, are defined over Oracle, and Teradata and the. Spark job now has access to all that data through, sequel, server. Right. So you can easily integrate all your data together through sequel server and feed it into your machine learning model training your, data scientists. Don't need. To have the data exported. Out of those systems and put on their laptops, as bad. That's. Bad I won't name names but, I went to go visit my bank, a. Big. One and I was I was very. Appalled by the security, pattern they had around what they were trying to do right so, do not export, your data out of your you know proprietary. You know very secure, systems, onto people's laptops and things like that to do analytics.
Right Keep. That data inside, of sequel server and have. That data you know be queryable, through, sequel server never leave that boundary and you can, use spark, ml to, do your model training as well so we really have the entire pipeline of, machine learning, covered. For you by the big data cluster we, can ingest, data in through, spark streaming, or through sequel server integration, services, we, can store that data inside, of the data pools, inside, of the master instance or an HDFS. We. Can then do data. Preparation, using. Spark we. Can use either spark, ml and all the libraries that are available through that like tensorflow and cafe and so on or. We can use machine, learning services, built into sequel server or we can use R and Python there to train our models and once, we have those models produced we can operationalize, them either inside of the sequel server master, instance or pretty. Soon we're going to show you how you can actually take those models run, it through a toolkit will provide and, we will automatically, wrap that model, with, a swagger, based REST API and, then, automatically, provision, it for you on top of the kubernetes cluster and. Now. You can generate a client-side, API like. This for, any programming, language you want and all, of your applications, can now hit that REST API and. Operationalize. Your model that way so. Let's say you had a model that was like an image classification, model, your. Application, developers can now submit an image to. That REST API and, they'll, get back to respond, it's like oh that's a puppy oh that's a dog you know that's a cat whatever and it, just makes it that easy to operationalize. These models for people. And. We can deploy it in a scalable architecture where, if you need to bump up the number of REST API containers. That are providing that model as a service, no, problem, is kubernetes, you click a button and it provisions, a couple more pods for you very. Powerful. So. If you think about the four V's of Big Data and AI. Sequel. Sort of big data clusters really help you do these four things the. First is that we're going to improve, the velocity, of your, data, you're. Not gonna have to ETL, around your data as often anymore you're. Gonna go get the data from, the source at the time that you need the query or you need the data and you're, going to be able to do that fast, because, you have this scale out compute our Kotecha and the caching, and the data pools. And. You can use spark which is a distributed, compute engine to do all of your data preparation if. You're, running all of your data through a single. ETL. Server to, do all of your preparation of your data and moving it around you're. Doing it in a way which is you. Know by definition bottlenecks. By the capacity, of that one server with. Spark you can do everything in a parallel, compute, environment that can execute it across a scalable, number of compute nodes. We're. Also going to increase the variety of your data by giving you access to lots of different types of data whether it's structured or unstructured you've. Got graph inside, of sequel server now you've, got JSON and XML inside, of there and you, can also go get data from other data sources like Oracle or ter data and bring that all together into one place and combine it together and so you have a greater variety of data which. Will improve the quality of your machine learning as well we're. Also going to improve the veracity, of your data by ensuring that there's not any data, quality, issues that are introduced, as part of your ETL pipelines, and like constantly, transforming, that data as it goes from one machine to another and so on and we're. Going to give you real-time access to that data nobody. Wants to make business decisions based on data that was from yesterday. That. Doesn't make sense we, need that data right now we, need to be building machine learning models that are basis based on the data right now and. We're also going to give you access to a greater volume of data whether that volume is represented, by the scalable, storage architecture, of HDFS, that you can scale up to petabytes, of storage or, in, the sense that you have access to a greater number of databases that you can bring in through data virtualization, either. Way you're, increasing the total volume of data that you have available to your machine learning.
Now. One very interesting thing that's in development right, now is. HDFS. Tearing. So. A. Lot. Of people are adopting, these data lakes they have data lakes that are on-premises, they, have data lakes which are in the cloud people. Have data lakes that are data lakes of data lakes I call. Those data puddles. Our. CTO, says that was a boring marketing, turn we should call it data lagoons. But. That's that's the kind, of thing that's happening now and. What. We want to do is we want make it easy for you to keep your data in one place but, be able to access, it from another so. This is where HDFS, tiering comes in this is actually a technology that's recently. Been added to HDFS, itself, and we're going to light up inside of a big data cluster what. Allows you to do is like let's say for example that you have chosen to use Azure data Lake as your your, data Lake but. You have an on-premise, big data cluster, as well and you want your applications, that are on premises to have access to that big data data Lake no, problem, you can set up HDFS, tiering between the two and the, files that exist in the data Lake can be available to your, HDFS, that's on-premises, and the, files aren't actually stored there in HDFS, on-premises, there, they're just like virtually, represented there, and when. You from, the point of view of a spark application, running inside of your on-premises, big, data cluster, they look like regular files, but. When SPARC or sequel goes to read it, HDFS. Will automatically, go and get that file from the Azure data Lake and materialize. It in memory in that HDFS. Inside of your big data cluster on-premises, and. From. That point forward is just another file you can just read and write to it just like you normally would and you. Can flip it around the other way so your maybe your files are stored on premises, but you want to tear it through as your data Lake and then be able to use Azure services. Like Azure machine learning for example to access that data that exists on premises. So. Now we want to show you a, few more demos of some of these things where you can use spark, and HDFS together, to. Do data. Preparation, and machine learning. So. Let's. Connect. Up to this cluster I have here now. For, demo, purposes, this cluster happens to be running in in Azure kubernetes, service because we wanted to show you how you could run this in Azure kubernetes service but this could be an on-premises, data center as well it doesn't really matter it's just kubernetes, and in. This environment here I have HDFS, and. This. Is where you can kind of browse your files you could it's just like a file explorer you can view, all the files in your HDFS, you can download them you can preview them you, can do interesting things they can upload files and this. Is the interesting thing here is I have this mounts directory. And. So. This is a directory. That is mounted on Azure data Lake and, I, can browse the, files and folders that exist in Azure data Lake underneath that mount point as though they were files and folders in my on-premises. Or in this case that as your IKS based a big data cluster. So. Remind blowing like it's not actually, there but we are able to virtually represent, that here and.
I Can just right click on this and preview, it and it, will actually go get that file for me from Azure data Lake like, that and I can actually see the file inside of here. But. Maybe that's not enough let's actually do some analytics against, it. So. This. Is our notebook experience, here this. Notebook experience, is built on top of Jupiter, as part of Azure data studio and it. Has a familiar experience, in the sense that you have these cells where you write code whether it's Python or Scala or R and you, can execute each cell independently. And get back the results, from your query and the, results, can optionally be stored inside of the notebook file itself, to make it easy for you to share your, analysis, with other people by just simply sending them a file. So. What. We can do now is we can execute this cell and what this cell does is it goes and reads this CSV, file that actually, happens to be an azure data Lake into a data frame then it shows us the content, of that file. So. Now I'm using spark I'm reading a CSV file but it's from Azure data like and. Now I want to create, a. Spark. Sequel table over the top of that and, now we can query it using, traditional, SQL syntax and. The. The scenario here that I'm doing is we've got a diabetes, data set this is a very common, data set that's used for like, machine learning demos, and the, idea here is if you want to use machine learning to predict, whether, or not somebody will have diabetes. Based upon some of their, attributes. You know what's their age what's the gender what's their glucose. Level and so on and so. This first sequel query that comes back it shows us you know the insulin, level of the people by age and so maybe that's a good way for us to just you know visually, look at this and see if there's any correlation you. Can see people here that are kind of higher up in the age spectrum have a high level of insulin but, then so do some of these people down here that have been probably, staying up too late in eating, doughnuts or something right so. That's. Not a good way to do it so let's use machine learning so here we can use SPARC to do a feature, ization, of the, data and, once. We have the feature ization defined, here you can see some of the different features that we have of our data and now, we can run it through an, algorithm like a k-means algorithm to. Actually. Classify, all this data and then we can start to do some predictions based on that. You. Can see this is just a very simple experience, of like just running through these notebooks and getting the data back you can look at it and you can just run your code right so, now let's do a prediction let's see if BMI.
The Body, mass index is a good predictor of whether or not somebody will have diabetes and. We can see here that the spread between you, know the BMI of somebody that does have diabetes, and something that does not is pretty big 35, versus 31 so that's a fairly good indicator of that now. We can see whether or not pregnancies, is a good indicator. Of whether or not somebody, will, have diabetes or not and not. Surprisingly, the number of pregnancies that somebody has is not, a good predictor whether they will have diabetes or not okay. So this is how we can bring the power of machine learning through, all of the SPARC libraries, that are available to. The data that exists inside of HDFS, whether it's the HDFS, inside, of sequel server or, inside. Of Asscher data Lake or even other HDFS, is like a cloud era or Hortonworks HDFS. Alright, so now I want to turn it over to Ronnie to do a like. A demo of data preparation, using SPARC cool, Thank. You Travis good, afternoon, one it's. A pretty mind-boggling. Huh, so what Travis just demoed so, so. I'm gonna show you some of the phases of data, preparation, now if you data. Preparation is one of the important, phases of the evolution, of data as data flows through the various stages and, traditionally. Data scientists spend a significant, amount of their time preparing. The data in a way which, they can consume later on so, what we have done in our notebook experience, with an azure data studio is we wanted to make at the rate of scientists more empowered, with the tools we have so, that they get a data preparation package, out of the box for them and this, data preparation package, which I'm going to show is actually a package, which has been developed. By Microsoft, Research so. Here I'm gonna show a sample file here it's called artist txt. And if you can look at this file you can see that they have field, descriptions, at the top there, is a lot. Of there's a like white spaces in the table there's some, blank white. Lines then, there is a pipe command here, and you. Can see that there is a the structure. Of the data is not formatted, pretty well they have some currency, code here now. As a regular, data scientist, if I have to process this particular. File I would need to write complex. Regular expressions, exactly, figure out how many lines to skip exactly, figure out why where my white spaces are and this can be a very. Time-consuming at, times right so what we did was in our, integrated, notebook, experience, which we have in Azure data studio. We. Have a package, and this, package, comes with in the notebook experience, itself it's called the pros code accelerator, the code accelerator, what it means is we are empowering, data scientists, to be more effective, by generating code for them a code, which gets generated by, looking at the sample of the file and making, a guess of what, the best optimization, code would be in order for them to generate that file so, here I have this artist a txt file and I, am going to pass in that filename, basically.
Just Two pros and let's, see what happens. Here. You go so pros what it did was it pros, generated, this particular, line of code for me it figured, out the exact, number. Exactly. What the delimiter, was exactly. How many rows to skip and generated, this code for me now as a data scientist I can take this code and run or even include, it into my production quality code as well so, what I'm gonna do is I'm gonna copy/paste, this particular code. And. Then. I'm basically passing, in the artist a txt file so the data which was unstructured, completely. Had a lot of characters, in a lot of blank spaces finally, immediately. Got some structure to it now one, of the fine things is you might ask me that okay say I'm not a Python, developer I want to do generate, my code in PI spark because we are doing spark and spark gives us the flexibility. Of running distributed. Workloads, much better right during, the phases which Travis was saying that that is one of the main benefits, of using spark, so what I can do is I can comment this particular line here. And. Now. I say okay generate code for me in PI spark context. Here. I have PI spark context, of the code which was generated first from, pros so pros is giving the flexibility, of generating, code into multiple languages as well now, if I just take this particular line of code. Which was generated and I have a sample another notebook opened, where I'm going to just, run that particular cell and. This. As you can see as Travis, was mentioning, that we, have multiple kernels, we support in our notebooks so do. When you're connected, to this notebook experiences. You by default get connected to the PI spark kernel this is the kernel which allows you, to submit your spark jobs so basically, it's connected to this particular, cluster and now I'm going to just run this code. And. This. Is also an aks cluster we redeployed. Just. Just. Open up and you know the book here. You're. Running production pool code. Here so that's. See. For this way I have, to restart the spark. Context here so that takes a little while. So. While, this spark, application, is running let me also show you some of the examples which we have done in our integrated notebook experiences, so if you have a local Python, developer one of the things which data scientists.
Do A lot is they, install, custom packages, custom packages from tensorflow. Scikit-learn. Matplotlib. Now, what, we have done is we also have an integrated manage packages, option, which, will allow data scientist to easily install, custom packages, and, ok. Ok. So this, is a fine example it's giving me an error saying that okay I need to install this particular. Packages. Here, so. Come. On. Some. Demo under pressure yeah. Try. To coffee this guy. Joining, those onto the sparks in it with me yeah. Probably. Just. Okay. So, so. Somehow the module, pandas is not working and I apologize, for the for, this demo mashup but so, basically what it does is with this code you would be able to submit this code against the cluster and you'd be able to load. The exact same Frank file from HDFS, file as well now what I think you just got the wrong copy/paste. Right because you have pandas running again in size burg I. Think. Is just a copy-paste there yeah, copy that again. You. Got pandas there. Okay. Pat. Okay. Come. On you can do it. You. Now, you see some of the files which got generated. From theis part using, the artist a txt file okay, so one, of the things I would like to show, in addition, is for example say you. Want to submit a spark job and one, this is one of the things which is very common, for data, scientists to do again submitting spark jobs against the cluster so what we have is we have made it simple for data, scientists to actually submit spark just from the cluster directly. So I'll say a test ignite, here. And then, I'm gonna copy over the path to where my, where. My jar file is now, this jar file can basically be, files, which, you are have pre compiled in a different environment whether, you're authoring, your code and vias code or in IntelliJ, or in Eclipse you, have compiled, a jar file and now you want to submit this jar file against, this particular cluster, so. It's. On your Visual Studio. I won't, risk copy-pasting.
Anymore. So. This so as you can see the spark job has been submitted to this particular cluster and what, in what we basically did, was we have integrated ourselves, with like, contributor back into, the ecosystem so, here, you can see the link to the spark UI so, now if I switch and click. You can see that this Park job was exactly submitted, into this Park job history server and this, also gives me some of the enhancements, which we did on top, of the existing spark, UI which the community already has this, is the spark application, and job graph viewer now if I actually play, the job it actually, goes through the stages in which spark, actually submitted, the job in this, gives me a, representation. Of how much, resources park is actually consuming. As as it's, doing the distributed, processing over, this big data file thank you so much today. Demo. Under fire well. Done sir. Okay. Good. So. That's just kind of a quick tour of some of the things you can do with spark inside. Of your big data at cluster, and. Really the idea here is is to make it easy for you to manage your, entire machine, learning pipeline, from ingestion of the data through. Storing, that data in various, ways being, able to do the. Preparation, tasks. That we saw today even, using technology, from Microsoft Research like pros and then, you can train. Your models store. Your models inside of sequel server or HDFS, score, against them operationalize, them all in one integrated. Platform. So. If you just step back and look at what we announced around sequel server 2019, big data clusters it's really three things the. First is a data virtualization, capability. That allows you to integrate your data from multiple data sources and not just simply query them but query them with amazing, performance. Because of the data pools caching, it and the compute, pulls doing the cross partition, aggregation, and shuffling of the data, secondly. Big. Data clusters, integrate, together sequel. Server and SPARC and HDFS. As a single deployed. Solution, that is provided, by and supported by Microsoft, and lastly. Does a complete AI platform. That allows you to do everything through your entire AI pipeline. And integrate. Together all, of the data through the data virtualization, this. HDFS. And produce. Your analytics, on top of all of that. In. Summary, it really drives your innovation, it allows you to integrate all that data manage. All of that data and analyze all, of that data, so. Where do we go from here. Like I mentioned we've been working on this project for about a year it, is now in public preview. The. Sequel. Server 2019. Preview. On Windows and Linux is, completely, open anybody can go get that you just go download it or docker pull and run a container whatever you want to do but, the big data cluster, part of sequel server 2019, is currently. Something that you need to sign up for this, EAP early. Adoption program, site and we. Will gradually, roll it out to customers as we go and the reason for that is really just because we want to have a, really close relationship with, the customers that are actually deploying these big data clusters so that we can learn from them, as we, go here, obviously. This is a huge leap. Forward in terms of what sequel, server can do and the, architecture, is somewhat. Complex and it's involves things that people in. The data space are still learning like containers, and kubernetes and you, know sequel server customers, in general are not that familiar with Linux and so there's a lot that we need to help customers through in this journey, towards sequel server and big data being combined together so we want to help customers do that and that's, why we have this early adoption program where people can sign up and we'll, have PMS, on the team like me and Ronnie that'll be assigned to work with each of these customers, to help you as you try to deploy this and start.
Getting Your hands wrapped around kind of this idea, of a big data cluster, and how you integrate it with your other systems like Oracle and maybe, your existing, Claudia. Or Hortonworks clusters, for example. So. Please. Go and sign up if, you're interested in this and you. Know we'll be available we have some of the other PM's up here in the front row to answer any questions you might have here after the session and then, please come back again, tomorrow morning and 9:00 a.m. and, we'll, go another level, deeper, in terms of how this all works and really learn kind of the details of all of this so thank you guys for coming out to think I really appreciate it.
2018-10-15