DEF CON 29 - Sheila A Berta - The Unbelievable Insecurity of the Big Data Stack
- Hi everyone, welcome to my talk on big data insecurity. I will talk about how we can analyze these big data infrastructures from an offensive point of view. Before starting, let me introduce myself briefly. My name is Sheila, I work as Head of Research at Dreamlab Technologies, a Swiss Infosec Company.
I'm an Offensive Security Specialist with several years of experience. And in the last time I had focus on security in Cloud Environment, Cloud Native, Big Data and related stuff. Okay, so let's go to the important things. There are some key concepts I will like to explain before jumping into the security part. Probably the first thing that comes to mind when talking about big data is the challenge of storing large volume of information, and the technology that will take care of it.
Although that's correct, around the storage technology, there are many others of great importance that make up the ecosystem. When we design big data architectures, we must think about how the data will be transported from the source to the storage, if the data requires some kind of processing to be consumed and how the information will be accessed, right? So the different processes that the data go through are divided into four main layers that comprise the big data stack. We have the Data Ingestion, that is the transport of the information from the different origins to the storage place.
The storage itself, the Data Processing layer, because the most common is to ingest raw information that later needs some kind of processing. And finally, the Data Access layer, basically how users will access and consume the information. And let's add one more layer here that is not part of the big data stack, but we have this layer in all the big data infrastructures.
The Cluster Management is really important. So for each of these layers, there is a wide variety of technologies that can be implemented because the big data stack is hugely big. These ones are just a few of the most popular ones. For example, Hadoop for the storage. Spark and Storm for processing. Impala, Presto, Drill for accessing information.
Flume, Sqoop for data ingestion. Zookeeper for management, for example. So when we analyze an entire big data infrastructure, we can actually find many different and complex technologies interacting with each other, that they meet different functions, according to the layer of the stack, where they are located, right? So let's see an example of a real big data architecture. Here we have two different clouds, one in AWS, and another one in any other cloud provider, both are running in some Kubernetes clusters that are serving different applications. And we want to store and analyze the logs of these applications.
So we will use Fluent Bit to collect all the application logs. Bring them to Kafka for the first cloud and stream them using Flume and Kinesis to run on-prem, Hadoop cluster. So within the Hadoop cluster, the first component that will receive the data is Spark Structure Streaming. This one will take care of ingesting and also processing the information before dumping it into the Hadoop filesystem. So once we have our information here, we want to access it. So for that we could implement, for example, Hive and Presto, or instead of Presto we could use Impala, Grid or any other technology for interactive queries against Hadoop, right? And if we are developing our own software to visualize the information, we will probably have an API talking to the Presto coordinator and a nice front end.
And finally, we have the management layer and here it's super common to find Apache's Zookeeper, to centralize the configuration of all these components. And also, an administration tool, like Ambari or a centralized lock system for cluster monitoring. So this is an example of a real big data architecture and how the components interact with each other.
So back to security, the question is how we can analyze these complex infrastructures. I would like to propose some methodology for this, where the analysis of, is based of, of the different layers of the big data stack. Because I think that the good way to analyze big data infrastructures is to dissect them, analyze the security of the components layer by layer.
In this way we can make sure that we are covering all the stages that the information we want to protect to go through, right? So from now on, I will explain different attack vectors that I've found throughout this research for each of the layers. Okay, so let's start with the management layer. Zookeeper, as I said, is a widely use tool to centralize the configuration of the different technologies that make up the cluster. Its architecture is pretty simple. It runs a service on all nodes and then a client, let's say a cluster administrator, can connect to one of the nodes and update the configuration. So when that happens Zookeeper will automatically broadcast the change across all the nodes.
So, with this kind of node of the cluster, we will find the ports 2181 and 7888 open. Because these ports belongs to Zookeeper, are opened by Zookeeper, basically. So the ports 2181 is, is the port that accepts connection from client.
Should we be able to connect to it? Well, according to the official documentation of Ambari, a tool that is widely used for deploying on-prem big data clusters, Disable the firewall. These are requirements for installing big data clusters. So we can probably connect to Zookeeper.
How should we do it? We can download the Zookeeper client from the official website. Then it's just about running this command, specifying the node IP address and the 2181 port. So once we connect, if we run the help command there is a list of actions we can execute on relevant znodes. The znodes, or Zookeeper nodes are the configurations that Zookeeper organizes in a hierarchical structure. So with the ls and get commands, we can browse this hierarchical structure. We can find very interesting information about the configuration of all the components that make up the cluster.
Like Hadoop, Hive, HBase, Kafka, whatever, right? And of course we could use it for fire attacks. We can also create new configurations, modify existing ones, delete configurations. These actually will be a problem for the cluster. Some components might go down because, Zookeeper, for example, is commonly used to manage the Hadoop high availability.
So if we delete everything, the cluster might run into troubles. So I wont run demos of these because it's a pretty simple attack. But is actually quite impactful.
So what about Ambari, this are pretty popular, open source tool to install and manage big data clusters. And it has a dashboard from which you can control everything whose default credential are admin/admin, of course. But if they were changed, there is a second door, absolutely really to check. Ambari uses a Postgres database to store the statistics and information about the cluster. And in the default installation process, the Ambari wizard asks you to change the credentials for this network but it doesn't ask you to change the default credential for the database.
So we could simply connect to the Postgres ports directly using these default credentials. They are user: ambari, password: bigdata and explore this Ambari database. We will find here two tables.
The user.authentication and users one. So if we want to get the username and authentication key at once, we need to do this inner join query between those two tables. The authentication key is salted hash. So the best thing that we can do here is just update the key for the admin user, for example. I log in to the Ambari source code to find Ambari salted hash. Here we have the hash for the admin password.
So now we can run an update query. And once done we can log into the Ambari dashboard with the admin/admin credentials. Well, I know that if this happen it's pretty stupid but it's actually worth to check because Ambari controls the whole cluster. If you can access this password, you can do whatever you want over over the cluster. And as the default installation process doesn't ask for these credentials, to change them, you can most likely compromise them in this way. Good. So the important thing in the cluster management layer
is to analyze the security of the administration and monitoring tools, right? So let's now talk about the storage layer. First, first of all, it is, it's good to understand how Hadoop works. It has a masters layer architecture and two main components, the HDF, that means Hadoop distributed filesystem and Yarn.
So the HDF has two main components. The namenode that saves the metadata of the files stored in the cluster, runs in the master node. And the datanode that stores the actual data and runs in this slave nodes, right. And, on the other hand, Yarn consists of two components, as well.
The resource manager located on the master nodes. It controls all the processing resources in the Hadoop cluster. And the node manager installed in the slaves nodes that takes care of tracking processing resources on the slave node, among other tasks. But basically, what we have to know is that the HDF, that is the Hadoop filesystem, is where the cluster information is stored. And then Yarn is a service that manage the resources for the processing jobs that are executed over the information stored. Basically it's stored.
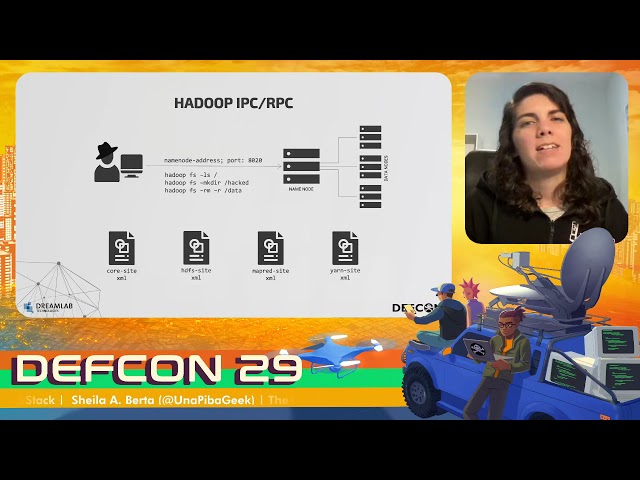
So when it comes to the storage layer, we are interested in the Hadoop filesystem, right? So let's hear how we could remotely compromise it. Hadoop disposes an IPC port of 8020, that we should find opened in Hadoop clusters. So if we can connect to it, we could execute Hadoop commands and access the stored data. However, this is not as simple as the Zookeeper example was. So managing to do this is a little more complex, right? There are four configuration files that Hadoop needs to perform operations over the Hadoop filesystem. And if we take a look at these files inside a namenode, we can say that they have dozens of configuration parameters.
So when I saw that, I wonder, if I'm an attacker and I don't have access to these files, how can I compromise the filesystem in a remote way? So a part of this research was to find among those dozens of parameters which ones are, a hundred percent requires, how we can get them remotely from the information that Hadoop itself discloses by default. So I will explain now how we can manually craft these files, one-by-one. Let's start by the core-site XML file. The only information we need to have for this file is the namespace.
This is pretty easy to find, Hadoop disposes by default a dashboard on the namenodes, on port 50070. It's a pretty high port. We can actually see it without authentication. So as you can see here, we can find the namespace name.
So I will hide my target cluster. And that's all we need for this file. Then we need to craft the hdfs-site file. It's necessary to know the namespace that we already have from the previous file.
And we also need the namenodes IDs, and the DNS of them. So we could have one, two or more namenodes. We need to provide the ID and the DNS for all of them in these files.
Where can we have these information? From the same dashboard? We have the namespace here, the namenode ID, and the DNS, right? So we just need to access this dashboard on each namenode. Remember that this is on port 50070. Another alternative is to enter the datanode dashboard.
Port 50075. And then we can see all the namenodes at once. So the next file is the mapper-site one.
Here we need the DNS of the namenode that hosted mapreduce-jobhistory. We can try to access the ports 19088 on the namenode. If we can see this dashboard then that's the namenode that we are looking for. We already know its DNS from the previous dashboard. Right. So. Finally, we need to craft the yarn-site file.
Again, we need the namenode and DNS. In this case, the one that hosts the yarn.resourcemanager. So we can try to access the board 8088. And as we see this dashboard then that's the right node. And here we can get its DNS, of course.
So all these dashboard are exposed by default and don't require any authentication. But if for some reason we cannot see them, we can try to get these required information through Zookeeper with the attack I showed you earlier. Because Zookeeper also has all these information, right? Cool. So once we have the configuration files we need,
the next step is to start Hadoop in our local machine and provide it with those files to perform the remote communication. As I didn't want to start Hadoop on my local machine, I build these Docker file, feel free to use it. It's pretty comfortable. You should need to change the Hadoop version to match the version of your target cluster, right? So from now on, this is going to be our Hadoop hacking container running on the attacker machine, right? Good. So let's run and get the shell inside it. We can create the config directory to place the XML files we have crafted before. And you also need to copy this log property file, inside this folder.
And another thing I did was to delete the host file to write the result of this namenode DNS. You can actually use the IP addresses on the XML files, but for some reason I had better results in doing this. Okay, so we are ready to go. Just pass to Hadoop this config directory, and you can execute for example, an ls command. So voila, we can see the entire Hadoop filesystem from our remote attacker machine.
But before jumping into a demo of this, I would like to mention that most likely we will need to impersonate HDF users. For example, if I tried to create a new directory using the root user, I cannot. So we need to impersonate a user that has privileges within the Hadoop filesystem. That means one of these ones.
Fortunately, that's very easy to do. We just need to set these environment variable with the Hadoop username before the command. And that's all. That will allow us to create directories and also will allow us to delete directories and files. So we could wipe out the entire cluster information. Okay. So let's see a demo of this.
Here, I have my files, the core-site with the namespace. I also have the HDF file. This is, has more information. The namespace.
And also the namenodes. For the namenodes, I need to specify the DNS. I have two namenodes in this case, so I need to specify the DNS for both of them. And in the last property was something I had to add for this specific cluster. The mapred-site has the DNS for the mapreduce.jobhistory address,
the namenode that has this resource. For the yarn-site, I had to specify the DNS as well for the resourcemanager node. So once we have those files, we are just ready to go an we can execute Hadoop commands over the remote filesystem. If we check the help for Hadoop for the fs commands, we can find a super common command for any UNIX system to move, copy, delete, move files, whatever.
To impersonate we need to specify this environment variable as we saw before. And here we can create directories or we can modify files or delete also any directory, right? Good. Good. So let's now talk about the processing layer, and how we can abuse Yarn in this case. So back to the Hadoop architecture, just to remember.
Yarn task schedules processing jobs over the data. So these jobs execute code in the datanodes. So our mission here is to try to find a way to remotely submitting an application to Yarn that executes our code or a command that we want to execute in the clusters node. Basically I achieve our remote code execution through Yarn.
We can use the Hadoop IPC that we are, we were using in the previous attack. It's just necessary to improve a little bit our yarn-site file. We need to add the yarn.application.classpath property.
This path used to be the default path in Hadoop installation. So it should not be difficult to obtain this information. In the example, here, we can see the default path for installation using the Hortonworks packages. Then these other properties optional. It will specify the application output path in the Hadoop filesystem. It might useful for us to easily find the output of our remote code execution, but it's not necessary.
And something I would like to mention that I didn't say before. If you can access these panels that we have seen under the /conf, we can find all the configuration parameters. But you cannot just download and use that file. We still need to manually craft the files the way we were doing it. However, if something is not working for you, here you might find what's missing.
For example, here we have the, the path that we are looking for for the, the property we have to set in this case. Good. So okay. So now we have improve our Yarn file and we can submit the application through Yarn. The question is, what applications should we submit? Here our Hortonworks provides a simple one. That is enough for us to achieve the remote code execution that we want. It had only three Java files.
Because Yarn applications are developed in Java, but there are a lot of Hadoop libraries necessary to include and use. So it might not be so easy to develop a native Yarn application, but we can use this one for our purpose. It takes as parameter, the command to be executed on the cluster nodes. And the number of instances, which is basically, on how many nodes our command will be executed, right? So we will clone this repository in our Hadoop hacking container and proceed to compile this shell application. We need to edit the pom.xml file and change the Hadoop version to match the version of our target.
This is really important. Otherwise, this is not going to work. So once we do that, we can compile the application using mvn. Good.
So the next step is to copy the compiled Yarn into the remote Hadoop filesystem. We can do it using the copyFromLocal HDF command. And after that, we are ready to go.
In this way, we can submit the application through Yarn. Passing as parameter the command that we want to execute and the number of instances. Here, example, I have executed the hostname command over three nodes. And we are going to, to receive an application ID. It's important to take note of it, but it's even more important to get this finished status because that's means that our application was executed successfully.
And now what, where can we see the application outputs? It's what we are interested in, right? Well, we can use this command path in the application ID we got in the previous step. And the output is going to be something like this. We have executed this command over three nodes. So we have three different outputs for the hostname command. Of course, we can change the hostname command for any other, right? So let's see a demo of this. Here, I have improved the Yarn file to have the path I need to add.
I have my simple yarn application from Hortonworks. And I already uploaded it to the Hadoop filesystem. So remember, you can simply copyFromLocal and just upload the jar to the remote Hadoop target.
And now with this command, we have to specify the local path of the Yarn file and the command that we want to execute, and the number of instances, the nodes and the remote path. So with these commands, we are going to get our application ID and the status. So now we need to use this application ID.
In my case, I need to move the output from one directory to other one. Just to allow yarn to find the, the output in the next command. It might be not necessary for you. So with a yarn command, we can just get the output of this application. So we are going to see the outputs for the three nodes.
We have the hostname output for the hadoop1, the first node, hadoop2, and hadoop3. Good. So let me show you one more. I submit one more application before to dump a file of the nodes. In this case, the /etc/password file.
So here we can see the password file for the three nodes, as well. So basically you can change these and execute whatever command you want. So that's pretty easy to use. Yep. It's also, should be quite simple to change these Yarn application to execute perhaps a more complex command.
Just keep in mind that any changes must be made both in the application master file, as we can see here inside and and also in the client file, right? So for example, if we want to get something like a reverse shell on the cluster nodes, it's possible. But keep in mind that this is a shell that it starts finished. So we may need to use other alternatives, like backdooring the crontab with the Yarn application, for example. So you can execute this command with the Yarn application and then back through the crontab, and then you will have your reverse shell on every cluster. Sorry, on every node of the cluster. Good.
I can't help but talk about Spark in this section. Spark is super popular, widely implemented technology for processing data, as well. It's generally installed on top of Hadoop and developers make data processing application for Spark.
For example, in Python using PySpark. Because it's easier than developing a native application for Yarn. And also Spark has other advantages over Yarn.
So as we can see here, Spark has its own IPC port on 7075, sorry, 7077. We can submit a Spark application to be executed on the cluster through this port. Is easier than we can. And here we have an example. This small code will connect to the Spark master to execute the hostname command on every cluster node. We should simply need to specify the remote Spark master IP address, our own IP address, to receive the output of the command and the command itself. And then we should run this script from our machine.
We don't need anything else. It's quite simple. But I am going to talk in depth about this because there is already a talk a hundred percent dedicated to Spark. This was given at Defcon, last year. So I actually recommend watching this talk. The speaker explains how to achieve remote code execution via Spark IPC.
That is the equivalent of what we did with Yarn. So keep in mind that the Spark may, or may not, be present to the cluster. While Yarn will always be present in Hadoop installations. So it's good to know how to achieve remote code execution, via Yarn and also via Spark. As we have the possibility to abuse this technology as well.
Awesome. So let's take a look at the ingestion layer, now. If you remember from our big data architecture example at the beginning of this talk, we have sources of data and such data is ingested to our cluster using data ingestion technologies. There are several ones. We have some design for streaming like Flume, Kafka, and Spark Structured Streaming, that is a variant of Spark. And then others like Sqoop, that ingest static information.
For example, from one data lake to other data lake. Or from one database to a data lake and so on. So from a security point of view, we need to make sure that these channels, that the information go through from the source to the storage are secure, right? Otherwise an attacker might interfere those channels and ingest malicious data. Let's see how this could happen. This is how Spark Streaming or a Spark Structured Streaming works.
It's a variant of Spark that ingest data, and also process it before dumping everything into the Hadoop filesystem. So it's like two components in one. So Spark Structure Streaming or streaming can works with technologies like Kafka, Flume and Kinesis to pull or receive the data. And also has the possibility to just ingest data from TCP sockets.
And that could be pretty dangerous. Here we have an example of how the code looks like when the streaming input issues a TCP socket. It basically binds a port to the machine. So abuse this is super easy.
We can use Netcat or a favorite tool, and just send data over the socket. And it works. What happens to the data that we ingested will depend on the application that processes it. Most likely we will crash the application because we may be ingesting bytes that the application doesn't know how to handle. Or a byte might end up inside the Hadoop filesystem. That's also likely. So it's important to check that the interfaces that are waiting for data to be ingested cannot be reached by an attacker, right? And regarding Hadoop, as I said, it's more of a static data.
It's commonly used to insert information from different SQL databases into Hadoop. Analyzing a Sqoop server I found an API exposed by default on port 12000. We can get the Sqoop software version, for example, using this query, but there is not so much documentation about the API.
And honestly, it's quite easier to, um... abuse this using the Sqoop client. So something important is to download the same client version of the server.
For example, this already is 1.99.7, we should download that version of the client from this website. Good. So what can we do? Well, we could, for example, ingest malicious data from that database that belongs to the attacker into the target Hadoop filesystem. That takes some steps. We have to connect to the remote Sqoop server, create some links.
This is provide Sqoop with the information to connect to the malicious database and the target Hadoop filesystem. And then we have to create a Sqoop job specifying that we want to ingest data from this database link to this other HDF link and store it. So this is quite easier to understand with the demo. So let's see video demonstrate. So here I have my Sqoop client, and I connect to the remote Sqoop server. These are the connectors we have available.
We need to create a link for the mySQL database, the remote attacker database. So I will specify the mySQL driver and the remote address of the database, some credentials to access with. And then most of the parameters are optional. So I will just create it.
And also we need to create a link for the HDF target. Here we have to specify two parameters. The first one is the remote IP address of the Hadoop IPC. In this case, it's in the ports 9000, but it's going to be most likely in 8020, as we saw before.
And the Conf directory is a remote path, not a local one. It's a remote path. That by def... It's going to be the Hadoop installation path by default. So now I hear on it, I specify on it, the path of DEXO machine, but it's going to be most likely lines, /etc/hadoop/conf. So good now, so now we find, now we have the, the links we have to create a job and the job we are going to specify that we want to inject data from the attacker mySQL database to the target HDF.
So we need to specify the name of the table we are going to ingest and then most of the parameters are optionals. So I'll, I leave it blank. So once we create the job. Ah, also, here we have to specify the output directory and that's also important. That's the remote directory in the Hadoop filesystem.
So, right. Now we have our jobs, ingest-malicious-data job. We just need to start it. This is all we are going to see in the attacker machine, but to show you that we actually ingest the malicious data, I will login to the remote machine that has the Hadoop filesystem, just to show that the data was actually ingested in the filesystem.
Here we have the hacking Hadoop and the hello, blahblah, malicious data that was in my remote mySQL and I ingested it into this group, into their Hadoop filesystem via Sqoop. So keep in mind that you can ingest malicious data, but you can also, um... export data because Sqoop allows you to import and export. So you can do this in a reverse way and still steal data from the Hadoop filesystem into your remote mySQL database, for example. Good. So finally, let's talk a little bit about the data access layer.
Back to our architecture example, we saw that it's possible to use different technologies for data access. In this example, we are using Presto together with Hive, but there are many others. And when it comes to Hive and HBase, these are HDF based storage technologies, but they also provide interfaces to access the information. For example, Presto needs the Hive metastore to create information and store in the Hadoop filesystem.
So this technology expose dashboard and interfaces that can be abused by an attacker if they are not rightly protected. For example, Hive exposes a dashboard on port 10002 where we can get interesting information and also an idea how the data is structured in the storage. The same for HBase. And regarding Presto I found this tedious login form where a password is not allowed.
It's quite curious because it's a login form, but you cannot enter a password. I know that you can set up one by, by, button, but by default, it seems to be this way. So you can write admin user there and enter. And there is a doc for, that show some information about the indirected queries being executed against the cluster. Good.
So as I said, this technology expose several interfaces. It's common to find at least a JDBC one. For example, in Hive, we can find it on port 10000 and there are different clients that we can use to connect to it.
Like SQRL, for example, or even Hadoop includes Beeline. We can connect to the remote Hive servers just specifying the remote address. If no authentication is required, of course, but yeah, there's usually nothing by default.
And Hive has its own commands. We need to know them to browse the information. With show databases, we can see the databases in the cluster. Select one and show its tables. And then we have syntaxes to insert, update, delete like any other SQL database.
Good. So I running out of time. So let us provide some recommendations as conclusion. Many attacks that we saw throughout this talk were based on exposed interfaces. And there are many dashboard that are exposed by default. So, if they are not be being used, we should either remove them or block the access to them using a firewall, for example. If some components need to talk to each other without a firewall in the middle, then we should secure the perimeter, at least.
The firewall has to be present despite the official documentation ask for disabling it. I believe that we can investigate what ports needs to be allowed in our infrastructure and design a good firewall policy rules. Do remember also to change all the default credentials. Implement any kind of authentication in all the technologies being used. Hadoop support authentication for the HDF.
It's actually possible to implement authentication and authorization in most of the technologies that we have seen. But we have to do it. Because by default, there is nothing implemented. Finally, remember that in the big data infrastructure, there are many different technologies communicating with each other. So make sure that those communications are happening in a secure way. Good. So in the next weeks I hope to be able
to put some more resources about the practical implementation of security measures. So for today, that's all. Thank you for watching my talk and here's my contact information in case you have any questions. Please feel free to reach me out.
Thank you so much. Bye, bye.
2021-08-07