Process Data Analysis and Visualization at Covestro The ProDAVis Digitalization Initiative
My name is Esteban Arroyo, I'm a data analysis and digitalization expert at Covestro headquarters in Leverkusen, Germany. I have a background in industrial, electrical engineering and process automation. Hi, I'm Philipp Frenzel. I'm also I'm a process technology expert. I'm also also located in in Leverkusen and my background is chemical engineering, focusing on process design and optimization. Our company Covestro is a world leading chemical manufacturer of high tech polymers. We have 16,800 employees and over 30
production sites worldwide. Our portfolio mainly comprises of polyurethanes, often used in insulation and homes in cars and houses. Polycarbonate, primarily used in the automotive, electronics and medical industries, and coatings largely used in vehicles, buildings and sports apparel. Last year, professional had a total revenue of 14 point 6 billion euro and since March 2018, we are part of the DAX index as one of the 30 biggest companies in Germany. As part of cholesterols effort to remain a global leader in the high tech materials field, we have launched the company wide Digital Transformation Program, digital archivist digital art cholesterol seeks to leverage the benefits of digital technologies, such as advanced analytics, machine learning social networks in e commerce in three main areas, namely digital operations, customer experience and business models. Of particular interest for this stock is the area digital operations. Here the focus of
digitalization has been set on leveraging a vast amount of processed data to increase the reliability, efficiency and safety of our manufacturing processes. This should be achieved by devise methods to collect structure visualize and analyze data in order to predict process behaviors and enable them by useful use cases such as predictive maintenance and process optimisation. align with this vision. We have launched tip pro Davis digitalization initiative. Pro Davis, which
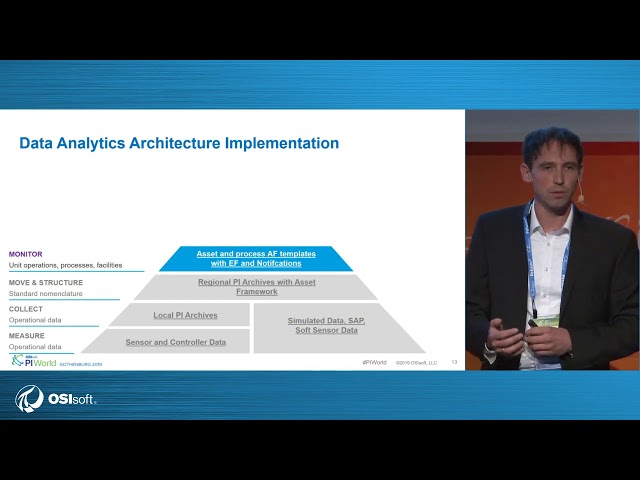
stands for process data analysis and visualization is composed by a multidisciplinary group of engineers from different commercial divisions. with expertise in key areas such as process design, simulation, advanced process control, data science, OT in it. The goals of Davis include to enable efficient analytics both in production and technology centers. to standardize the way people access and visualize data to capture, share and retain knowledge to face the ongoing generation change in to enhance collaboration between experts. To translate this soft goals into a technical realization, we have implemented a data analytics architecture with the BI system as possible. Every part of this architecture is mapped to a workflow step required to achieve our data analytics goals. Concretely, in the first step of the workflow,
we measure what well data from our sensors and controllers which constitute the first level of the architecture, then we collect, this information will be collected in local pi archives. In a similar way, we measure and collect information from simulation environments, MEMS systems and self sensors. As next step, we move in a structure this data into regional by archives with Asset Framework, where we standardize the data based on consistent naming and structural conventions. As next step we monitor how well by means of acid in process AF templates provide us with analytics, Event Frames and notifications. The next step is simulate, or more concretely integrate the results of our online simulation environments with our process measurements, which allow us to detect deviations and therefore process anomalies. The next step is to analyze and derive thereby useful insights from our data by incorporating self service analytics tools. And finally, we
predict and generate process KPIs forecasts by means of machine learning artificial intelligence tools that can help us to optimize maintenance and operational activities. The main outcomes of these steps can be then visualized in a one stop shop visualization interface, namely by vision, where we have developed a system navigation cockpit with standardized process and asset dashboards. I know at first glance, this architecture might be a bit hard to grasp. Let's break it into pieces for a better understanding. For that, I hand over to my colleague Philip. Thank you, Esteban. And good afternoon from my side. Esteban just gave us an overview of our data architecture, the remaining part of our presentation, we will dive into the steps of the workflow. And we'll explain the components of the data
architecture. Let's start with the very bottom of the pyramid, measure and collect. In our production plants, we have a lot of a lot of sensors, and control our data. That data is stored in local pi archives. And these local pi archives on geographically distributed around the world juicily very close to the corresponding production sites. Sometimes we need for our data analysis stuff, other data sources like data from SAP data from the lab, or simulated data. And you can
imagine that it could be very complicated to connecting the different data sources and different local pi archives, especially when every data source has its own workflow to get access to the data. So what we need is a kind of centralized data infrastructure and, and a standardized view on the data sense data sets. And thanks to the support of our experts, we have luckily in the company, this was achieved by setting up regional pi archives. And during the setup of the regional pi archives, one key question was how to move and structure the data from the local pi archives, to the regional pi f cells. And having in mind that every production plant and every site has its own individual history, especially regarding naming convention. Okay, it's the next step is movement structure.
The first thing to do is to translate every tech name to the same naming convention. Because that's a regional PI Server, every tech name should follow that same nomenclature. And we are using a nomenclature called flock functional location. And this naming convention is based on four levels, we have the site and process the process area, the process section, and then the tech name. Changing these names requires a high amount of effort, but it's definitely worth it. Because then the second step is much simpler. The second step is creating an
appropriate tech hierarchy based on our naming convention, and that is much simpler, because the parts of the naming convention can be mapped one to one, to the elements or to the path to the levels in the tech hierarchy. As a result as a hierarchy that consists of all our PCT equipment, all of our sensors, we have the field. Of course, PCT equipment is only a subset of our assets. The remaining part of our equipment,
the remaining part of our equipment, our assets and those assets, I mean our unit operations like distillation columns, pumps, heat exchangers or reactors. Here we are using the same nomenclature, except that for the fourth level, we are using the asset name instead of the tech name. The result here is a second hierarchy, the asset hierarchy that consists of all the main assets, all our main unit operations, and these elements are based on these other so the unit operation, and these elements are based on AF templates, AF templates, and we have developed AF templates for our most common unit operations. We have the company okay at this point, we have to Different hierarchies, the tech hierarchy and the hierarchy. How are these two hierarchies related to each other? To that end, you see, on the left side, the tech hierarchy, and here, the elements function as data sources. On the right side, you see the asset hierarchy. And here's the fun elements functions as data consumers. And
the connection between both hierarchies is realized and form of attributes defined in AF templates. And this connection between data source and consumers via AF templates. This is our technical foundation to be enabled asset monitoring. And monitoring is exactly the next step. in our, in our workflow.
Let's talk about monitoring. The situation is that we have a lot of things to monitor. We have PCT equipment, and we have unit operations processes, entire facilities. And how should monitoring system looks like that provides information about the most important KPIs to do some monitoring stuff. And here we decided to go with PI Asset Framework. We are also using the analysis services using Event Frames and notifications. And on
the next slide, we will show you how we did the setup for such a monitoring system. You see on the left side a depiction of a very common distillation setup. The middle This is a distillation column, you'll see at the bottom the reboiler. This is a condenser and the feet to the columns preheated by a heat exchanger. This distillation set up as part of a plant was named
dy dx, located in Baytown. The process area is vo five and the name of the process section is Kf oh one and exactly these names defines the define the path and acid hierarchy. And the elements here are the the equipment we see here, this positions and the distillation setup. And we have templates for for for each for every unit operation we see here for the column for the reboiler condenser and the heat exchanger. And because this setup was really common in our company, so the reusability of the templates is also very high.
And this helps for the rollout. And also to keep the maintenance effort Low, low. Let's take a closer look into the heat exchanger template. This is a heat exchanger. Honestly a very well equipped heat exchanger. Because we have temperature measurements and flow measurements at both sides at the utility side and the process side. And one challenge here is that only by knowing the
name, for example, for this temperature, it's not possible to say this an inlet temperature if there's an outgoing temperature, is it on the process on the utility side? Or another question is, what is the corresponding flow meter to that temperature? Only by knowing the name, it's not possible not by using the attributes in the pi f templates, it is possible because what we do with the attributes, you add the meaning or the context to a PI tech. And exactly this functionality. Adding meaning or context to pi Tex is very valuable for me as a process engineer. This is not only easy. But there are also other advantages. One of the
advantages that I knowing the meaning of pi tech is it's possible to do automatic calculations of KPIs. And one of the most popular KPI for heat exchanger is the heat transfer coefficient or the new value. The heat transfer coefficient is defined by a function as a function of two way defined a temperature differences and a flow meter. And the heat transfer coefficient gives you an indication about how easy it is to transfer heat from the hot side to the cold side. And
therefore is also a good indicator for fouling. And thanks to the chemistry and our processes, our processes have falling tendencies. So we see an decreasing trend over time and the heat transfer coefficient. Of course, it's nothing new to do fouling indicator calculations, but only by using the templates It is, it is possible to to, to a roll out at a large scale. And that's advantages. And when you you can create Event Frames.
For example, when the heat transfer coefficient is reached a certain level event fame can trigger the notification to inform a maintenance engineer who can then schedule next cleaning activities. So important the heat transfer coefficient to to assess the performance of a heat exchangers, it's not always possible to do this calculation because of missing instruments. Or thanks to many colleagues, we have a lot of very accurate process simulation models in place. And we can use this first principle models to fill missing
instruments. And that's the one we'll show you how thank you for. Right, so the next step in the workflow is simulate more concretely how we integrate simulation results from online models and process measurements. This integration is basically realized by integrating the readings of our field devices with the results of online process models. These allow us
to increase the visibility we have of the process, the integration happens within our PI AF templates, and can be visualized in our PI Vision dashboards. Let me provide you an example of how this work. In the field. We have five temperature measurements to monitor the profile of this column. The blue points in this graph depict the respective values. The online simulation model of the column, however, computes temperature values for every column stage, providing us with 25 different values to monitor their profile. So you
can see here the orange points in the graph. Note here how simulation allows us a better visibility of the function of the column by providing us values for those temperatures that are not directly measured. If the model is accurate enough, this could be a viable alternative to replace missing instrumentation. Now imagine here the potential savings. When
considering that an installed field device measurement can cost up to several thousand euros. Not besides that this integration allows us to detect deviations between measured and simulated variables, which may indicate process anomalies. In fact, we have extended this comparison concept to do some sort of process wide monitoring. And this was achieved by developing tables in PI Vision. The columns of these tables
depict the current measured and simulated variables and their respective deviation. So by using a color multi state, it is pretty simple to glance at a glance to observe and sort process deviations. Now these process deviations could be mapped or coupled to Event Frames and be used to generate timely notifications. The question here is what to do once deviations have been identified. These take us exactly to the next workflow step analyze.
Aiming at supporting our experts during troubleshooting, the architecture has been seamlessly integrated to a third party analysis tools. This integration happens within our PI Vision templates or vision dashboards and allows our experts to move from monitoring PI Vision to explorative analysis in third party tools, such as seek and trendminer. This is as simple as initiating an on demand self service analytics session by only clicking a bottom in their respective dashboard. The initiated session will be pre populated with all relevant attributes corresponding to this asset or process and also offers an extensive set of processing algorithms that can be used to solve troubleshooting problems. Let me provide you two examples. Our experts detected an anomaly in one of our columns and therefore they proceeded to confirm troubleshooting by clicking the respective bottom in the dashboard, they initiated an on demand session in trendminer and perform a simple pattern recognition to see if this behavior has been previously observed. In the past. Few instance later results
were displayed. As a matter of fact, we have seen this behavior and the root cause of the problem was quickly identified. In a similar fashion, our experts success suspected at became behavior in the catalyst activity of one of our reactors, accordingly initiated an on demand session in see this time by clicking the respective bottom in the dashboard, and only with few steps, they could reconstruct the temperature profile of the reactor for several periods along the last seven years. The generated view as you can observe, allow them to verify the report trusses and generate a consistent and understandable report to experts in the management. While most common troubleshooting problems that our experts face daily, can be solved with these sort of tools. There are some more
complex troubleshooting activities that may require automated root cause analysis, scenario testing, or multivariate forecasting. This sort of problems can be best solved by using dedicated machine learning tools. These take us to the next level of the architecture predict. In order to enable use cases such as predictive maintenance, and process optimization, we have integrated in the architecture, machine learning artificial intelligence tools. An example of these tools is Pharaoh from Pharaoh labs. This tool uses based on machine learning to learn prediction models based on our PI historical data. This is an example of one model created
in Pharaoh to predict a complex case of falling in a heat exchanger. And these are three examples of the current tasks our experts perform with it. As you can see, in the left side of the screen, the following behavior index in this heat exchanger changes to in different campaigns, sometimes it's fast, sometimes it's slow, although we run the plant at the same rate. Basically, with the same conditions. Our experts don't really understand why sometimes it's fast, sometimes it's slow. So one activity they perform is root cause analysis using the software for automatically compute a factor importance report indicating the influence of different process variables over devouring. This information is used to identify those factors with more influence and take contractions to prevent falling. The second activities, multivariate
forecasting farrowed generates forecasts with associated confidence intervals, as we can see here. This is an example of a forecast for the heat transfer coefficient, which as Phillip explained us is an indirect measurement of faulting. So these sorts of graphs are used to plan maintenance activities on the heat exchanger. The third task is scenario testing. By using the tool, our experts can assess the impact of setting certain conditions on the influence factors over fouling what I mean exactly, so they can ask questions of the type, what will happen with the following. If we change this parameter in this way, to
specify a condition, you see the effect on the target, in this case, the heat transfer coefficient. As you can see here, by performing this action, we could increase the heat transfer coefficient of the heat exchanger and continue to operate. This are a few examples of how we use machine learning, machine learning complementing this way, our tool or set of tools for monitoring and self service analytics. As you can
see, we have different options to analyze, process behavior and predict what would happen in the future. visualizing the results of this variety of tools, however, can be overwhelming for some users. This reveals the need for a one stop visual interface that can combine all those results. This is precisely the last component of our architecture, which Phillip is now going to explain us. Thank you
Okay, now we have seen in the last slide that a lot of data is handled and generated by connecting different data sources by adding information to existing data sets or by simulations or calculations. But remember, that's the goal of the of the entire workflow is to, to assess or possibly optimize the performance of assets or processes. Therefore, it's important for the for the whole concept to have an easy and fast access to the data. And this is why we could pay to kind of
design the kind of one stop shop visualization consisting of a navigation cockpit to navigate through the informations through the data. And this will also consist of standard dashboards based on the template idea for our assets and, and processes. The visualization concept was developed in in PI Vision, and I will show you a few screens to give you an impression how that can be. This is the landing page of our navigational cockpit, accessible by frozen. Depending on your role, or depending on your interest, you can select between different views. And for this presentation, we have prepared few, two views, the asset view and the hierarchy view. This is a asset view. And
so the idea behind the asset view is that you have a very quick access to all equipments of one kind at once, for example, oil pumps, or heat exchangers, oil distillation columns. And this is very important for our asset engineers, who take care about the assets of the entire site, for example. And they benefit to have easy access to the important KPIs to assess the performance of the assets. Thanks to the template idea is this list is always up to date, you don't you have to create this visualization only once.
And then this dashboard pulls information from the from the AF structure. So the maintenance effort is also very low. The second, the second screen as the hierarchy screen, basically, you can access the same information by both wins. The only difference between the few views is a way of navigation. here for the hierarchy view, the idea is to to get information about the asset associated to one plant and this is important for our plant engineers who take care of one plant. Okay, you have basically the same information by both views. And the endpoint of the navigation concept is always the standard dashboard for the unit operations. And I will show you one dashboard.
This example is for for visually, this is a visualization for the distillation column. You'll see on this side the distillation setup with reboiler condenser and the pre heater. You'll see some process variables and on the left side, you'll see the diagrams with the most important process variables like the temperature pressure profiles also level of column button How can you work with such a dashboard? It's beginning you see there we have relatively steady state operation normal operation Everything is fine. But later on we see some hiccups. Typically the process
engineer have already a gut feeling what can go wrong for example, one one effect for distillation column is called flooding, flooding is when you have too much vapor in the column and this vapor flow prohibits the liquid to trickle down. And when you have a flooding situation the column is not able to do its job to to separate the mixture okay when you have the feeling, it could be flooding, your fear some some pre configured troubleshooting screens. So you can click on the flooding screen and then a new diagram flow was pre configured process wherever very errors that are necessary to assess Do I have a flooding situation or not. And we see here the same time range at the beginning more or less steady state and then the Hickok hiccups But versus time resolution, it's not possible to do any further analysis. So we click to zoom
in. And instead of one day, we see now only four hours. And this is a good time resolution to see the effect. We start also with a steady state conditions, and then two things happened, the level of the column decrease and the pressure drop increases, the level, the level, the level of the button vessel also column, and the level decreases, because the vapor prohibits the liquid to trickle down celebrity quizzes. At the same time the pressure drop increases, this is a pressure drop along the column. And the pressure drop increases, because our liquid hold up and the column increases too. And this is a very strong indication for flooding situation. And the next question
is, why do I have a flooding situation? This is due to high load or due to falling within the column? To answer that question, we see some causal process variables that characterize the load of the column. And the green one is the inflow and the power of the system. And it's a point in time, and the flooding situation started, as a side note remains the same. And after operators recognize that something goes wrong, they even reduce the load by stop the steam supply. And but by doing this, even the pressure drop still increases.
So this is a very strong indication that we have flooding due to fouling and not due to the load. In this case, we can very quickly to that conclusion flooding due to falling, but sometimes it's more difficult. But even then, the the screens are helpful because it's the kinds of our starting point for further analysis. For example, the Self Service analytic tools or machine learning tools, Esteban mentioned before, okay, this was the visualization concept, an example from the visualization concept as the last piece of, of our workflow. So we are almost at the end of our presentation, and over to Esteban again, who will summarize and conclude the presentation for us. Thank you, Philip. All right. So let's summarize the scope and benefits of Davis
by comparing what we had before and after the project. Before pro Davis, our process, experts were often confronted with difficult data access to local by archives, due to IT issues, different naming conventions, and in general a lack of data context. Our solution was to provide them with a regional standarized platform based on Asset Framework, where they can efficiently access the data in the context they require. We've
puerperal Davies, our experts have virtually hundreds of islands solutions for data analysis. Every expert had an Excel table with macros and Visual Basic code to perform calculations. Our solution was to provide them with a set of seamlessly integrated tools, both self service and machine learning, where they can learn models, analyze process behaviors, and share their insights with other experts. Before previous, our experts had limited options for data visualization, they used to rely in process books poorly maintained, they needed to install software and keep files in their machines to be able to visualize parts of the plat. Our solution was to provide them with a one stop shop virtual interface in PI Vision, where we developed navigation cockpit with standarized asset and process dashboards. Since then, they don't need to install any software they can access the data simply by a web browser. And the platform is centrally
maintained. They know at any time that they are working with up to date versions of the dashboards. satisfied with the current results of the project, Jane Arnold, head of global process control technology at covestro said and I quote, by exploiting the PI system we have, we managed to create a scalable data analysis platform that allows our process experts to visualize and analyze process data in an efficient fashion.
Not only have we made it easier for them to turn data into valuable insights. We also have laid the robust basis for continuously harvesting from Digital opportunities. Naturally, not all has been straightforward in this journey. Along the way, we have found several technical and organizational challenges. And we have learned some important
lessons we would like to share with you to conclude this presentation. The first challenge was the large number of assets found in process industries. We found that we have hundreds of asset types in our processes, modeling all of them would require a huge effort. What we learned while deploying AF templates is start by the most critical and common assets, those that really need to be monitored, and those that can be easily deployed based on templates. The second challenge was the high variability within asset types. We determined for
instance, we found, for instance, that columns are critical and common assets, and therefore we need to monitor them. However, when we started the task of creating a template for a column, we realized we have different column configurations in different properties. So the lessons we learned there is develop templates that are general enough to capture the most important asset characteristics. Keep it simple. Another lesson, we learn there is create
dashboards that are capable of dynamically adapt to the different asset configurations, use fishing multi states and collections to avoid the need of creating several dashboards for the same asset type. Remember, we don't want to replicate the process books of the past. The next challenge was missing instrumentation. While deploying AF templates, we were really happy or we had the templates, let's deploy, we realized that in many cases, we were missing instrumentation to be capable of properly monitoring the performance of our assets. If installing additional instrumentation is not an option for you, due to high cost, for example, explore the possibility of using rigorous simulation of soft sensors as replacements. Deployment was and is still a challenge for us.
Certainly, deploying AF templates in different facilities around the world is a time consuming task. But we have learned so far is that by partnering with third parties, it is possible to automate part of the deployment process in guarantee consistent system maintenance. Finally, in more in the organizational aspect, we found some resistance to the digital transformation. What we learn in this aspect is involve stakeholders from the very beginning, listen to their pain points and propose useful painkillers explain the experts that the new technology is not there to replace their past efforts, but rather to support them. Show simple by compact concrete use cases with added value. Explain management, how
they can easily profit from the new technologies. And the final tip is do dissemination work. This is a point we have been working in. And we will continue doing so in the future, to bring
data in data analytics possibilities to as many people in the organization as possible. With this, we conclude our presentation. Thanks a lot for your time. Any questions for step one? Come on. It's after lunch, everybody should be awake. So I did have a question around the Self Service analytics. great use of not only PI Vision, but also our external partner technologies. How do you decide between one or the other? And what to use between PI Vision and say, see, for that example? This is a great question. Actually, we have
explored both of them as alternatives for self service analytics. They are both really good at that. Some functions might be better than one some functions might be better than the other. Typically, you could solve the same problems with both. The only difference is you will follow a slightly different workflow. We can tell you which one is better, it's up to you to test them. And find that by yourself can just say that both
are really good pieces of software. Along those lines, the link that you followed to go from PI Vision outward to seek the seek display, is it prebuilt? Correct. That is our dashboard for visualizing an asset or a process. Basically, that asset will generate an URL and this will open a session in the third party tool, either sequel trendminer. And by default, this session will be pre populated with all attributes for that asset, leveraging the Asset Framework. So basically, we just go to the Asset Framework and collect all the information that is available for the asset and make it available on seek or trendminer.
Thank you, any more questions? Going once place, gentlemen, thank you very much. Thanks.
2021-04-04