Deliver Enterprise AI at Scale with Dataiku and Microsoft OD417
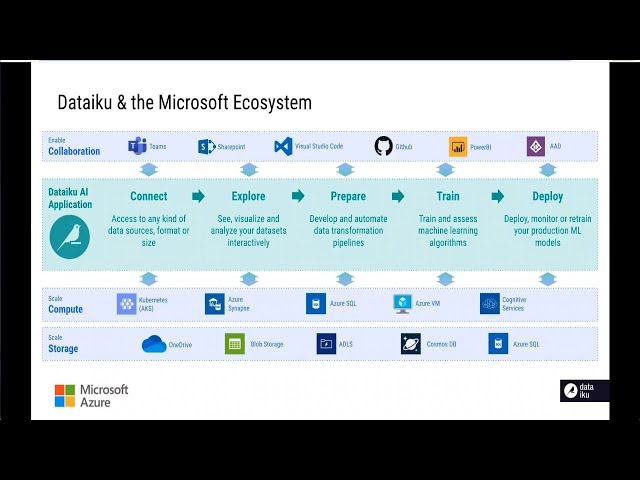
[Music] hi everyone my name is greg willis and i work at daily road key i'm the director of solutions architecture um welcome to this presentation thank you very much for attending i'm just going to start off with a few slides and then we're going to move over into a demo so first of all data right q is a global isv partner with microsoft i've been for many years uh recently awarded the partner of the year award in the france intelligent cloud category now i'm going to step you through a little bit about what data iq is how we work some of the technical details and the architecture and then switch over to a live demo to show you some of those features so what makes data iq unique uh you can sum it up in one sentence in that data iq provides scalable end-to-end multi-persona collaboration in a single product which means scalable data preparation and machine learning processing for thousands of users end-to-end ai ml lifecycle management supporting multi-persona users from no code business analysts to full code data scientists and everyone in between with real-time collaboration between those users and all in a single ready-to-use product which is called data iq dss data science studio the individual elements are not unique but the combination of them in a single product is for example you can find other products in the in the ai and ml space that give certain end-to-end capabilities but usually within different products that are broken out and they have to be integrated together with different interfaces and they're usually targeted at different personas collaboration too has been a core part of data iq from the beginning but these days you can find pretty much everybody using that word but what does it really mean if you dig into it it's typically about an individual sharing an asset such as a model or a notebook rather than true real-time collaboration that you find in data iq to give an example of the difference the former is like creating a pdf document on my laptop and putting it in a network drive and changing the settings so that a colleague can come and read it and make a copy and use that document the latter is more like a google drive doc or something similar when multiple people are all working together in real time editing commenting adding deleting um and and actually increasing the quality of the asset and the speed at which it can be created the building and delivering ai scale requires integrating dozens of technologies to seamlessly work together across multiple domains providing features within data machine learning uh operations and platform and infrastructure data iq dss is a ready to use full stack data science platform in which all of these different technologies from things like python and kubernetes to jupiter notebooks are already integrated our joint solution puts microsoft at the center of this technology ecosystem and thus makes all of data iq's capabilities available to microsoft's users and the power and scalability of the azure cloud available to data iq users including no code low code and full code users sql focused users plus architects that maybe may need to use multiple languages and tools so how can you actually deploy data right q there are three different ways the first is a fully managed self-service offering called data iq online for small customers the second is data iq a custom option data iq custom and this basically is if you have a on-prem customer or maybe a customer that's on the cloud that they want to deploy into their own tenant with their own specific requirements perhaps around security or other things like that the third is data iq cloud stacks where we provide a way for customers to automate management of all of their data iq dss instances in their own cloud subscription but what is data science anyway so let's take a step back you can find a lot of venn diagrams on the internet for pretty much everything including data science but this is the one that most closely matches my own thinking for me data science is an interdisciplinary field which combines business expertise computer algorithms and statistical methods to extract insights from various data sources most typically it does this by using supervised machine learning algorithms to train models using patterns in historical data for example house price fluctuations or activities that indicate financial fraud and then uses that model to make predictions on new data data iq manages that entire data science and machine learning life cycle starting with the iterative design phase through deployment and automation in production systems all the way to monitoring and feedback this whole process is often called ml ops the main node type within data iq is called the design node which is where most of the work happens connecting to data exploring analyzing training machine learning or deep learning models etc once the project is complete there are two further node types that support operationalization of the project or perhaps individual models which are the automation node for back scheduling monitoring and the api node for real time rest based machine learning api service deployments so what does that mean how does data iq integrate into a microsoft ecosystem for example well you can see data iq providing the end-to-end capabilities necessary for a single integrated data science platform but we have a lot of integration points with microsoft services all the way along that process from integration into teams for example to extend into external collaboration capabilities using sharepoint for document sharing visual studio code is an alternative ide data iq comes built in with its own git repository but you can also integrate into external ones like github you can extend the visualization capabilities of data iq by integrating into power bi and on security side we integrate with azure active directory but when we really take take advantage of the full kind of power and capabilities of microsoft azure cloud is in the compute and storage layers where we have a very tight integration into azure kubernetes service we use that as a multi-purpose computation cluster for python for spark for r for api service deployment and scaling many other things we also integrate into azure synapse azure sql into cognitive services to extend pre-built machine learning and deep learning capabilities and on the storage side various things such as onedrive blob storage adls gen 1 gen 2 etc so now i'll switch over to a demo and i will just come out of this hopefully that's come through correctly what we can see here if you're still with me is the home screen of data iq when you first log in this is kind of what it looks like you can customize this but essentially what you're seeing is a list of your projects and data iq being a collaborative platform each of these projects would have a team of people that are working on it and each project would typically be about a particular use case so we have lots of different use cases here represented by the different projects i'm going to open up this one here which is about predicting churn and specifically this one is built on telco telco data so we're looking at historical data where we know which customers churned and what we'd like to do is use that data to actually gain some some some value from it for our business so for example we could predict which customers are likely to churn in the future and then prioritize those customers based on perhaps how valuable they are to us so their total value and the potential lost revenue if they did churn and then feed that data into a downstream crm system so that they can prioritize a certain action to take maybe for the very high value customers they'll call them on the telephone directly maybe for medium value ones they'll send them a voucher in via email or something like that um so what you see here is the the project home screen um you can see some contextual information about the project you can customize all of this there's a built-in wiki etc you can add links and things so if i'm a new team member coming into this project for the first time i can find everything that i need to get started straight away you see some summary information like data sets and models and notebooks and stuff like that i can have a to-do list i can have a timeline here of my activities so i see a summary of things that have maybe changed recently i can also start discussions i can send messages to other people in the project and tag them to ask them to maybe look at certain things or update something for me i can also see things like the activity the history of the project so who's been working on what and even say a punch card to see when people are working on it at different times of day and things like that and as i mentioned before data iq comes built in with its own git repository repository so everything is tracked and versioned and you can go and see all of the changes and actually even down to the the diffs in in individual files so i can see which things have changed and i can even for example create a new brand from a from a change or revert a change of a particular file or of a particular version of the project itself the whole project um but the main view that you have within data iq is the flow so i'm going to go to the flow and what you see here is a visual representation of all of the steps that have been created as part of this project and as we saw in the presentation data science is an iterative process where you're going to connect into multiple data sources you're going to need to probably cleanse that data aggregate it um do common types of transformations such as maybe pivoting tables or running data cleansing jobs and things like that you might need to use different technologies you might have some users that are going to use primary visual interfaces and some users that are going to use different types of programming languages and then you're going to use that cleansed and enriched data to build your machine learning models so let's take a little step-by-step walk through all of those different different steps what you see on the screen these blue squares are data sets and these can represent basically any kind of underlying data data source so in this case we've got data which is stored in azure and that could be within visual blob storage it could be in azure adls gen 1 or gen 2 it could be using a hdfs type of file system access on top of azure storage we've also got a table down here from an sql type of database this is actually running on synapse um and then in between the the blue datasets what we have are yellow visual recipes so these are recipes that are pre-built into the product ready to use straight away and these are for completely no code users so if you're a business analyst or a citizen data scientist or even a data scientist that wants to be able to get up and running very quickly and maybe iterate something build an mvp without having to get into the code um these are very quick and easy ways to do very powerful data transformations so you have all of the common types of things that you would like to do like stacking and pivoting etc joining data sets together and you can choose where things happen so if your two input tables are an sql table in synapse for example you can you can choose to actually run those in in database sql meaning that although you do everything visually behind the scenes data iq will transform your visual operations into native sql and it will push it down to run in the target system you could also choose to run it on spark if you have a spark cluster and data iq can actually provide a spark cluster for you in a completely seamless and managed way so if you don't have a spark cluster we can actually make that a very simple and easy option to use as an alternative data processing framework the other thing that you see here are the orange recipes and you have code recipes so for example this python recipe here and this is a way to directly add or write your own python code or r code or spark code etc you can see we've got um support for quite a few different languages and you don't have to choose one or the other you can see in this flow for example there's a straight python code recipe there's also a pi spark code recipe you can have an recipe in here some sql stuff a command line a piece of script or something like that as well so all those different users can use the tools and the interfaces that are appropriate for them and their role but still work together and collaborating in real time within this same project interface so what we have here is some data preparation steps as i said preparing the data and then what we've got here is a table which is a classic uh telco data the the telephone numbers and the and the state and things like day chart charges night charges uh evening charges international cores things like that and finally because this is the historical data that we're going to use to build our model we also know whether these customers actually churned or not so we can see which ones it was true for and now we've cleansed this and we've standardized everything enriched it the first operation we're going to do is this machine learning recipe here the green recipes to train an unsupervised clustering model so in this case we're using k-means and you can do that in a completely auto ml way within data raiku so if i open up here you've got this lab button here i can go down to the lab tab here and actually see i've got automl clustering i've also got automl for prediction and deep learning prediction as well and you can go as kind of shallow or as deep as you want so if you're a completely no code person you can go down a completely no code route and just use visual and automl interfaces however if you are a data scientist that wants to code and you want to kind of go into expert mode you can do that too if you've built python custom python models you want to bring those into the platform you can also do that so we've run this we've trained this model here and then we've scored our data on it to apply labels so i can see for example now within this data set as well as the churn information i have a cluster value from where i've applied that k-means model the next step is to then actually train a predictive machine learning model so here you can see i've got a prediction model which is a random forest classification model to predict either churn or no chair and if i open this up what you can see is i've got one version of this i could have had multiple versions and it will tell you which one is active and you can switch between the current one and previous ones drill into the the details of previous one so everything is saved and versioned and if i go back to the original analysis where this model was actually created from i can see all of the historical settings that we used i can see the different sessions where we ran our different experiments um so this was the latest one session two we saw that uh the one that we we actually deployed excuse me was the random forest actually the xg boost had a slightly higher score here the data right q is a completely white open box solution so you can go into the design tab at the top here and see all of the settings so even if you choose to go down an auto ml part where data iq will do everything for you and you don't need to see any of these settings you can still go in and open them up and have a look and change them and rerun it so maybe as a citizen data scientist i want to come in and see what settings are have been set here i want to see how we're handling the train and test data set maybe i want to override some of those settings i can see how it's handling the features automatically again i can go in and do that and change things like computation of missing values or the variable type etc do feature generation or reduction um or i can override which algorithms it's chosen to use um so data iq if you do automl it would intelligently choose a few algorithms to test and it will set default parameters but maybe i want to come in here and choose a different one maybe i want to run a logistic regression and i'm going to change some of the parameters in here i can do all of that and then i can rerun this and it will generate a new result for me once i'm happy with a particular model for example let's say this xg boost one i can go in and look at the particular details of that so i can see things like variable importance look up partial dependency between variables look at subpopulations so is my model actually fair so in order to combat machine learning and ai bias i need to analyze my model to make sure that it's behaving fairly across all populations of my data maybe for regulatory reasons i might need to explain individual predictions so i can do that too and then you get all of the typical tools and things that a data scientist would use to evaluate the performance of a chart and if i was happy with that i would then deploy it back into my flow so you see the deploy button up here i would click that and i could have multiple models deployed into my flow but i'll just keep it at one for now and we can see that other people are actually connected to this platform at the same time as i'm demoing so just to kind of emphasize the real-time collaboration aspects here and then the output data is our data set with our prediction value appended and we can see even the probabilities here as well so we can now use this data perhaps the the value that this customer currently generates multiplied by a probability of them churning if they're predicted to churn to get a potential revenue loss so we can use something like the prepare recipe and data right q which is general purpose and very powerful recipe to do custom data preparation data cleansing kinds of tasks but again without necessarily needing to write any code so you have lots of built-in processes here to do different things geographic operations mathematic operations data cleansing natural language etc but what i'm going to do is just replace these values turn them into numeric now i'm going to run a short calculation here an expression [Music] to actually convert that into a value which i can see over here which would be the kind of weighted charge that we would be uh potentially losing [Music] if this customer did churn so we could use that to then send that data out to a system a different system where it would get picked up by perhaps that crm system downstream so that somebody can look at the highest value customers and prioritize those for outreach well that was a very quick tour of a single use case in one project in data iq but hopefully that gives you a at least a bit of an idea a bit of a taste for for what data iq can do um particularly within the micro microsoft ecosystem working with things like azure kubernetes service to scale out machine learning uh processing as well as data processing um being able to manage smart clusters on top of kubernetes and and use uh docker environments uh containerized environments integrating into underlying compute and storage options such as synapse and sql server and azure blob and adls gen 2 and also being able to use things like cognitive services to do perform sentiment analysis and and other types of natural language processing the language detection entity recognition etc hopefully that was useful please come and find us again thanks very much bye
2021-03-06