Insight into edge to core data management and analytics THR2375
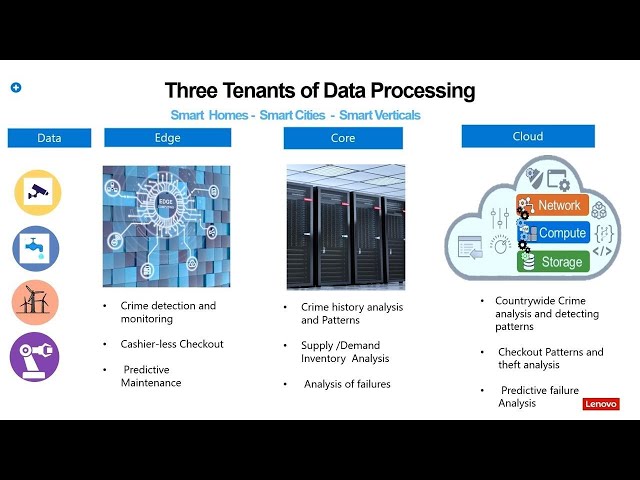
Good, evening folks, thanks. For joining my presentation, I'm precising. Toucher a product. Manager focused. On database and big data analytics, so. I have a short, presentation on, how to gain insights. Into. H4, and cloud, with, the sequel server 2019. At, the end of my presentation I got an interesting demo, how, sequel, server 2019. Process one trillion, records in. Under. 100 seconds period of time so, so. Stick, with us for, till end of the session for an interesting demo. So. Esther days in such as keynote he. Kind of highlighted, like the importance, of edge computing, it's going to be a revolutionary, so. On that note I want to ask what, percentage, of the data as per Gartner. That. That, what percentage of the data is going to be generated and, analyzed, at the edge. So. As, forgotten, report it is going to be 75 percent by. 75, percent of the data by, year 2025. It's going to be generated, and analyzed at the edge before, it moves into the for, our cloud so, that's why edge computing, it's going to be a lot of importance, as we, move forward and. All. The organization, our enterprises who's looking into building, this end-to-end, story from all, the data that is getting generated at the edge before. It moves into the core and cloud they got to pre analyze this data because, it is all related to the real-time real life events, for, example, chick-fil-a. Restaurant they. Capture all the point of sales information, from. Point. Of sales information from, their keystrokes, that is being generated as, the orders come in and then, they map this data with respect to what the that. They are the from the kitchen smart sensor and, adjust, the initial forecast if they have predicted for 2,000 people for orders and if, they see that they realize that okay that is not coming in that much so they are going to adjust that order based on that so, all this information has. To happen at the edge before, the data has to move to a code or cloud because. This is all real time real life events and the, same thing is for the cashier less checkout for, example, like, when you walk into any of the cash electric current like home before those things right the amount of commercial merchandise. You purchased, on your back, it doesn't. Matches with what. You carry out in number of scans so, that means it is immediately, has to alert otherwise, the. All, the retail store and are having severe, losses right so, the same thing is if there is any break-ins. For. For. A crime monitoring, it has to be alerted in. Millisecond. Or microsecond. Lightens your period so that's why the edge computing, is going to be a lot of important, as we move forward and the things that getting, processed in the core this in the traditional, data centers is more about the, massive, data analysis, all the things which is happening and the edge will move to the core that is in the data centers, and these, data massive, analysis, has been carried out and then. The. Intelligence, which is getting built like, you know so the example. The forecasting, for, the chick-fil-a restaurant our, effort or the retailer's checkout like the certain. Patterns, we're continuously. You are missing or certain tags right, in the cashier. Let's check out so, these insights, is fed back to the core rather. Fed back to the edge so there by the edge devices will become an intelligent edge devices and then. On to the cloud here, in the cloud part it is about even a larger scale analysis, for example here, I mentioned. About crime history analysis, and patterns here, in the core whereas, here in comes to the cloud your carrying out this chemistry, analysis, in a large scale even at a country level so, that is where that because the economics, of scale on the cloud is so beneficial so, they carry out this and I even a larger scale analysis. And the, second point is more on to the cloud is where they store lot of deep this data for a long term data retention. So. As we, move forward it is important, to architect, your solutions.
With Respect to data what, kind of data you want to store at edge how. It has to respond, and what data you are going to store it in the core and to the cloud so all these three the. Tenants, of data processing is very very important as we move forward so. With, that said when, you are dealing with the edge computing, right, you want the servers to be lightweight form. And can fit under the shelves right like because when you are dealing with in a retail store you don't want a big service to be carrying so, but this, servers to be powerful, enough to deliver. A solid. Performance, so, what I'm showing up here is an edge. Server, Lenovo things system SC 358, server this is what's shown in the yesterday, schemes such as keynote, this, server using. A sequel server 2019. Standard, edition as we. Scale this performance, from a four core systems, delivering, at 385, Mayer 385. K transactions, and I, increase this course from four core all the way up to 16 cores I'm going to hit one point eight million transactions, per second so, this is a hammer DB transactions, so. That's, a massive, amount, of performance. On a smaller footprint, right so that's why it's important, for an edge computing, and when it comes to the eye ops, it delivers, almost, 385, ki offs this is almost like you know a entry, level a solid storage array performance, so, a massive. Performance linear. Scalability it's, a perfect, a solution. For in if you are looking into any anything in the point of sales application or, any of the eight solutions, you're looking into deploying, in. The other use cases that I referred to them. So. Moving. From edge to core. And cloud I get another interesting, solution that we are working with the, Microsoft, another eight solution, I'll talk to this a little later on the. Current, cloud this, is the state of the. Traditional. Database and Big Data solutions, to, suit various, organization. Needs so, what we built is a different, architecture solutions. For example for any business critical applications, which. Requires high ability we've, developed the solutions, using the physical servers this. Will deliver a high performance, throughput, with, always-on. Availability, group so that thereby if you lose the server you're not going to lose any drop in performance but if you're looking at a scale out architecture for. Example massive. Amount of scale so with the sequel server we build these solutions. On hyper-converged. In. Franklin. X as well as an agile track HCI and. This. As you check HCI using, the sickle surgeon 2019. Is new, solution, that we announced. Exclusive. For the ignite conference I'm going to talk about this little more in detail that so. For anything if you are building any cloud native applications. So, we have that solutions, on a hybrid cloud using. Azure stack and Azure. So. All these data which is on a transactional, workload, will move into the data warehouse to, suit their whether, you have databases, 110 terabyte, or. Massively. Up to 200 terabyte regard, the solutions, taken care these are Microsoft, certified, solution, as you see here these are Microsoft, certified solution, which, is being validated.
Pre. Engineer so that if you are carrying. Out any data warehouse deployment, it you will provide a faster time to value and then. For a Big Data solutions, you. Know the. Traditional reference architecture, with the cloud heiress and Houghton was but. What it gets interesting, here, is. So. Microsoft. Announced an interesting, solution which, connects, the traditional, data warehouse, and the big data using. The sickle sort of big data cluster 2019, what. It will happen is going forward you're not going to be using. Sequel. Server 2019. For a database, a data. Warehouse or a, big, data cloud, errors are Doulton works so, you will combine these two under a unified database management, strategy, so. That's. An interesting solution be honest I got a good. Little. More details into that little later so. Here, is the sequel. Server 2019, solution which is built on that. I just racket CI Lenovo. Grinding, we call it as a thing catch LMX so what you see here is picture is as we, scale this thing Kajol MX which is a I just I could see a solution from, a to node all the way up to 12 North you, get a linear scalability, in performance, so, what we are showing in this chart here is for, a two node, 146. K batch, requests, per second this is it the sequel server batch requests, per second with, eight point nine million transactions. Per minute so, and if I scale this from, two node to twelve not so. The batch request, request. Is also scales, linearly. Where I'm going to hit a 900k, pass request per sec and. The. Transactions. First minute is whopping, 55 million, so that's a massive 55, million transactions, per minute so that's the amount, of performance. And the, scalability we are providing, this in a scalable configuration. So, you can pick up this two node configuration for, any Robo and you're in a front of its deployment but, this you can go into the the massive, scale enterprises, deployment, so they're by this solution, is scalable, from an entry level all the way up to you, know the high end enterprise requirements.
Okay. So, circle. Server is already, enabled. Connecting. Your sickle. Server to external, database, a external Big Data solutions, either cloud era Houghton was and I including. The Azure blob storage starting. Sequel server 2016, using. The poly based functionality. But, what gets exciting. Is. Seeker. Server 2019, big data clusters, can, not only connect to these big, data Houghton, what's on this but, they also can, connect to the other relational, databases like Teradata. Oracle. And even, to the your, db2 and. No SQL databases like cosmos, on MongoDB, so what does it mean for you is you're, not moving the data from other sources for. ETL, or alt jobs to, build the repos so, the, data stays there all the, data virtualization, concept. How you used, to do this VMware, or hyper-v virtual ization, concept, is being extended onto the data virtualization so, that means the, data stay sit there when, you fire a query it will go and fetch into the various, data sources and build a query and get back to building a report for you so, that's a, incredible. Benefit, that you're going to get so thereby you're avoiding all the ETL jobs and everything in the future. So. What, lenovo has done is. Carrying. Out the testing of these solutions on a lenovo a half, rack environment, so what is this off rack environment, consists of is by. The way big data cluster is built on a kubernetes, platform, so, what we used is that dedicated, one kubernetes, node. Call, it as a kubernetes, master, and the rest of the things is serves as a kubernetes, storage nodes. And in. That configuration, we. The, the, big data cluster has a four important, components, one is a storage, node this. Storage node is nothing but a HDFS. Like, if, you have used to the cloud eros or Houghton works they store the HDFS, layer the data node, what. Do you call it in the Houghton Watson cloud era is equivalent, here is a storage pool so, it is a massively, scalable a history, of s layer, and then. The, benefit of this big data cluster is it's a elastically, scalable, compute nodes so that means if you have a massive amount of data. That you need to pull it from different parts of the data sources you, can spin up as many compute nodes as possible so, that's the benefit of it's, a disaggregation. Of compute, and storage the, new paradigm, is everyone, is erupting, that's been benefited here in the big data cluster, and the, data pull the data pool is more about cashing, in the results right so if you are fetching the data from, other relational. Databases like from Oracle, Teradata, MongoDB. So, you don't want this data to be every time going in fetching from the other data sources so, they want to pre cache in these results so, the next time you fire a query saying that get me a data from Oracle get me a data from MongoDB, so, it is not going to go into fetching data, from these from. Computable, going to fetch from the other sources it is already pre cached so thereby, it will avoid all the data being fetch from this so it will have an instant results so, that's the benefit of the data fall and. The. Sequel server this is the master instance so that means whatever. The benefits you are going to get in a traditional sequel, server databases, you continue, to enjoy this with the sequel server master instance, so this is the four fundamental. Components. Of a big data cluster you should be familiar with and that is, being tested out with the Lenovo half rack environment. You. Know with the kubernetes platform. So. The next step so we wanted to show the. Performance and scalability of, the big data cluster. On. The Lenovo. Platform, so, we started off testing. Out a derivative of, TP CD s TP CTS in case we are not familiar with that it's a addition. Support system benchmark. Which is used by all the retailers so, what, it does is it will a complex. 99, SQL, queries, fetching. The data from, I mean, it has got a millions of rows of complex, queries multiple, table joins so, that's the TPC D s a derivative of that benchmark we have used for evaluating, the bench performance, so, when we fetch when, we started. With the 10 terabyte it fetched 56, billion rows and they, increase the data set from 10 terabyte, all the way up to 100 terabytes were able to fetch 566. Billion, rows so, as you see it's a linear, scalability, in performance, from 10, terabyte, all they were 200, terabyte fetching from 56, billion or a 556 billion so, that's the benefit of a big data cluster for you so. Uniform. Linear scalability, and as, far as the data loading, so when we loaded 10 terabyte of data it took around 3 point 7 hours and then, we increased up to 100 terabyte it is 38 of us so, there is a 2 important, point I want to highlight with this testing right one is, so.
That These queries, is a complex, read intensive, workload so, that means it illiterates that if you are running any big big, data complex, workload the, big data cluster on lll platform, provides the uniform scalability, that's, the rate, intensive, workload for. This loading, the data it's more about to write intensive, workload that means you're writing lot of data into the big data cluster, the, HDFS, layers has to provide that kind of a robust performance, that's, where we are getting this benefit. So. Now. Based. On this. 2, or 3 months of significant, engineering work what we are come up with is like you know the use cases how customers, can take advantage, of this big data cluster on lln of platform so what we are providing is a three level product, offerings a Star Trek configuration. Which is a fine, node configuration and. This. Will defines certain, amount of memory storage, it's completely. Flexible so. Based on your is cases you can change this however you need need to be and, just then, the next term would be a standard environment. Which, is a half rack environment, because, lenovo is working on this big data environment for, last 10 years so we have seen how customer, uses the big data environment with, the hot and worse and cloud era so based on that this, is the three levels configuration, just, Android standard, environment a half-track will get you around nine nine, service rather. Nine nodes and this is the memory and CPU configuration and, advanced. Environment, this is the customer who's building at an end-to-end, analytics, like the data is coming in from my spark and IOT. I want to generate the insights with all the machine learning built into it so that, is where we have built this an advanced environment by, the way I'm doing one more session on this tomorrow, a detailed, breakup session that'll, I'll provide how, you. As an end customer, take advantage, of this configuration, for your use cases whether you're building a data Lake or your edw modernization, or a machine learning so, this is a short. High-level, presentation, picture and be proning so, as.
Far As the use cases right so. The. Business intelligence accelerating. Any business images and applications, it's a no-brainer so because you are doing this for cycle server using this for long period, of time you continue to do that but, where the things get exciting or more functionally, gets added is building. The data legs so, now in future when you are building a data leg you don't need to use some, other big data platform because the big data cluster, and the, traditional data warehouse is built, into an one unified, platform so, that's there by you can take advantage of this build, a data like that you can integrate, a structured, data unstructured data end up the same unified. Platform and the, EDW modernization, so if you have an enterprise data warehouses, already so, and you feel that your data, versus yours not being utilized for the. Functionality, that is supposed to do so, you can portion I mean a, certain, portion of the data you can offload from traditional enterprise EDW. To, Hadoop, environment that. Is big data cluster environment so, you store all the high priority, data on the area W and Hadoop. In the Big Data cluster you can store the all the archived data so, thereby you, can not. Only reduce some amount of the software. Licensing cost and infighting, can get. Benefited, restoring the huge amount of data as well so. We are working with one of the leading telecom. Customer right now in the US who. Is that one of the subscriber, probably you will be using that as for your telecom. Carrier they, have this kind of a scenario we are helping about them, and streaming, analytics right which I talked about all the data which is generating, at the edge you want this what is happening right now so that, is where the information, is, being provided with the streaming analytics you can stream the data using, the the Kafka, and Apache spark streaming, and generate, the insights quickly and if, you are into a financial or, retailer you want building a new business model like the example I talked about like in a fraud identification. Or a fraud detection you can take care of through that building, a new machine machine, learning models. So. Now, how. Do we connect that the data which is generating, on the edge to, the big data cluster right so we have an interesting use case as well as a demo that we are doing at a Lenovo booth where, we are showing is in a mill. In a factory. All, the the data which is getting generated from the edge devices, like, whether it's a pressure temperature, all, these the. Sensors, that, the amount, of data you reach is getting generated we, are streaming the data live, and storing. Into the sequel DB edge this, is a new product that we are working with the Microsoft, is called as your sequel database edge so, this means the same engine, that you are used to particle, server they, were extended, tree onto the edge so small tiny, devices. You can deploy this sequel, DB edge and what. It will do is like it will provide the same functionality of the sequel server but it has got a lot of other functionality, like the, spark ml, so. If this was spark ml streaming.
And Some, of these information these, functionalities, added, to the DB edge thereby. So. These edge devices, will become an intelligent edge device and this, data will be passed on to the big data cluster, which I've spoke about so, here, you carry out all the massive analytics, on the big data cluster the intelligence, that you built onto this like the new machine learning models everything you feedback. Yeah. You feed that information back into the edge so, there by the edge devices, can be responding. To the if there is a temperature, spike, or a pressure spike so that so, whether it is for a factory or a retail, they can respond very quickly. So. Now, connecting. All these three dots so. Sequel, DBH running, on a Lenovo edge server 350. Pressing, this all the edge data, to the big data cluster, carrying out the massive analytics, and for, the long-term retention you're looking at carrying, out the even bigger, a large. Large scale analysis, you can carry out this on the same big data cluster on a case a case nothing but Azure, kubernetes, services, you can carry out that so, thereby you can build the, all the three tenants, of data processing as in one single framework. Policy. So. What. Lenovo Gayle help you to get started with a big data cluster is we, provide a complete, the. Server storage networking, all. Cable. Ranked, so, on delivered, as a one single unit so, thereby if. You want to get start and even the big data cluster we, are looking at getting the big data cluster pre-loaded, so that thereby you, can have this big data cluster up and running whether he wanted a quarter, rack or you want a half rack up these things you'll be up and running very quickly, so and we are also I'll, talk about this later so we are also working on a use cases like you have a certain use case you are building a data like so. We have a POC environment, that we can have help so, so. In addition to the solutions, as I said lenovo is working on this big data environment for, several, last ten years so, we have established a, big data benchmarks, using the TP CX BB BB stands for big bench so, what we are showing is that scalability. And performance benefit. Dow Lenovo, sr 650, server scaling, up to 36, nodes and, we, are providing a high, performance, this is the, 3.7. Million. Big. Bench queries, per minute so what this big bench does is structured. Data semi, structured data unstructured, data, so, it runs the queries on all these three data patterns, and comes, out with the results so that is what we are saying here highlighting, is so whether you're storing structure, and structure a semi structure this, performance. Benchmark, illustrates, that we provide, a better, performance, at a lower cost compared, to the number two under. Which I mentioned there so. Yeah. We have used the high one spark to illustrate the performance, benefit so this is the big data framework that you will be using in any other big. Data environment. In. Addition to the big bench, we, also have established another.
Performance, Benchmark, using the AI for all the I voted deployments, so what, we are showing is they another, level systems, we, are showing like you know delivering. 742. K IOT. Transactions. Per minute and. These. Delivers, at 56, 57. Percent. Faster and 10 percent lower rate compared, to the my other second. Vendor into this scheme and, we, are we are doing is like loading 1.2, to fill million, records into the HBase so, the IOT, transaction. Is all about loading the records high. Amount of Records loading into the HBase and they're showing that these TPC. X IOT. Platform can, perform to the scale that is required, as prescribed, by the TPC, body. So. Yeah. So we will use the HBase 2.1, and recover our serious 6.3. So. I want to leave you with this. Last slide it says if you are looking at building an end-to-end H core. And cloud analytics. So, we, can help you get started with a proof of concept or. If you are interested into the subset, of the technology, let's say I am totally interested, in the sequel DB edge or big data cluster, we, can get to the proof of concept use, thereby we can help you with a subset of that technology and, if, you are looking at a demo, platform how it can be scalable we can make that happen with the rapid scale so we have this Innovation, Center with is they will. Make it pre-configured. And make it available for you across worldwide, innovation. Centers whether it's in Morrisville in North Carolina for. The entire US operations or, stood, guard in amia and Beijing. So, respect. Of which origin, or which country you are looking at we can make that happen for. Building. Your enter, and data management with. That said I got a one pick short demo that I need to be sure, to show. So, what I am showing up here is in using, a Lenovo SR 958. Socket, system. On. Having. 224, horse, which, when. You do. A hyper threading is 448 course. Stretching. One trillion records one, trillion not billion one trillion records under, 100 seconds of period of time so, you. See here this, is the match in the kind, of performance like you know what sickle server is looking for a environment. That is being provided from Lenovo sr9 58 socket system so, you see, on this side like you know the all the, course is 100%, matched, out. So. This, is the kind of performance you need when you are deploying or. When you're processing typed immense amount of data right like any wanted entire, data. I mean entire course to be maxed out so that you will get this performance, in. A short period of time as, you see I think let me drag quickly so, to show.
So, Yeah, the, line item table that you see this is the one trillion records. So. This is the 1 trillion records and it, processed. 54. Terabytes. Of data so, the overall data set we loaded is 150, terabyte or of that 54, terabyte, it fetched one, trillion records I under. One. Minute. 39. Seconds, which, is under 100 seconds period. Okay. Let me drag this. Yeah, the query completion, so. One minute 39 seconds the query completed. With, that said I'm done with my presentation if, I'm happy to answer a Finnick any questions if you got thank you.
2020-01-18